Apache Beam + Kotlin 開発 実践入門
 Photo by tian kuan on Unsplash
Photo by tian kuan on Unsplash
どうも、こんにちは。Re:ゼロ2期 始まりましたね👏、 @silver_birder です。 最近、仕事の関係上、Apache Beam + Kotlin を使うことになりました。それらの技術が一切知らなかったので、この記事に学んだことを書いていきます✍️。
サンプルリポジトリは、下記に載せています。
Apache Beam とは
BatchやStreaming を1つのパイプライン処理 として実現できるデータパイプライン、それがApache Beamです。(Batch + Stream → Beam)
言語は、Java, Python, Go(experimental)が選べます。 また、パイプライン上で実行する環境のことをランナーと呼び、Cloud DataflowやApache Flink、Apache Sparkなどがあります。
※ Streaming処理は、サーバーの能力がボトルネックになりがちです。そこで、Cloud DataflowというGCPのマネージドサービスを使用すると、その問題が解消されます。
機械学習など豊富な 分析ライブラリ を使いたい場合は、Python、 型安全な 開発をしたい場合は、Java を選べば良いかなと思います。
今回は、Javaを選びました。モダンな書き方ができるKotlinでコーディングします。
セットアップ
ソフトウェアバージョンは、次のとおりです。
$ java -version openjdk version "1.8.0_252" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_252-b09) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.252-b09, mixed mode)
IDEとしてintelliJを使用しており、Kotlin SDK(1.3.72)が内蔵しています。
$ git clone https://github.com/Silver-birder/apache-beam-kotlin-example.git && cd apache-beam-kotlin-example $ ./gradlew build
パイプライン処理の概要
1. データの入力する(input → PCollection) 2. 入力されたデータを変形させる (PCollection → PTransform → PCollection) 3. 加工したデータを出力する (PCollection → output)
PCollectionは、ひとかたまりのデータセットだと思って下さい。
よくあるサンプルコード WordCount を例に進めます。
※ 元々は、ApacheBeam公式のWordCountがあったのですが、ローカルマシン単体で動かせないため、多少アレンジしました。WordCountは、ある文章から単語を抽出しカウントを取るだけです。
メインのコードは、こちらです。動かすときは、IDEからデバッグ実行します。(この辺りは省略します。詳しくはMakefileを見て下さい🙇♂️)
@JvmStatic fun main(args: Array<String>) { val options = (PipelineOptionsFactory.fromArgs(*args).withValidation().`as`(WordCountOptions::class.java)) runWordCount(options) } @JvmStatic fun runWordCount(options: WordCountOptions) { // パイプラインを作る(空っぽ) val p = Pipeline.create(options) // Textファイルからデータを入力する → PCollection p.apply("ReadLines", TextIO.read().from(options.inputFile)) // PCollectionをPTransformで変形させる .apply(CountWords()) .apply(MapElements.via(FormatAsTextFn())) // Textファイルにデータ(PCollection)を出力する .apply<PDone>("WriteCounts", TextIO.write().to(options.output)) // パイプラインを実行する p.run().waitUntilFinish() }
PTransform
Apache BeamのコアとなるPTransform についてサンプルコードを載せます。
ParDo
ParDoは、PCollectionを好きなように加工することができます。 最も、柔軟に処理を書くことができます。
// PTransformによる変形処理 public class CountWords : PTransform<PCollection<String>, PCollection<KV<String, Long>>>() { override fun expand(lines: PCollection<String>): PCollection<KV<String, Long>> { // 文章を単語に分割する val words = lines.apply(ParDo.of(ExtractWordsFn())) // 分割された単語をカウントする val wordCounts = words.apply(Count.perElement()) return wordCounts } } public class ExtractWordsFn : DoFn<String, String>() { @ProcessElement fun processElement(@Element element: String, receiver: DoFn.OutputReceiver<String>) { ... }
GroupByKey
Key-Value(KV)のPCollectionをKeyでグルーピングします。
import java.lang.Iterable as JavaIterable // PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollection<KV<String, JavaIterable<Long>>> val groupByWord = wordCounts.apply(GroupByKey.create<String, Long>()) as PCollection<KV<String, JavaIterable<Long>>>
Kotlinでは、Iterableが動作できないため、JavaのIterableを使う必要があります。
Flatten
複数のPCollectionを1つのPCollectionに結合します。
// PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollectionList<KV<String, Long>> val wordCountsDouble = PCollectionList.of(wordCounts).and(wordCounts) // PCollection<KV<String, Long>> val flattenWordCount = wordCountsDouble.apply(Flatten.pCollections())
Combine
PCollectionの要素を結合します。 GroupByKeyのKey毎に要素を結合する方法と、PCollection毎に要素を結合する方法があります。 今回は、GroupByKeyのサンプルコードです。
// PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollection<KV<String, Long>> val sumWordsByKey = wordCounts.apply(Sum.longsPerKey())
Partition
PCollectionを任意の数でパーティション分割します。
// PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollection<KV<String, Long>> var 10wordCounts = wordCounts.apply(Partition.of(10, PartitionFunc()))
StreamingとWindowing
パイプラインを、そのまま使えばBatch実行となります。 Batchは、有限のデータに対し、Streamingは無限のデータに対して使います。 無限のデータを処理するのは、Windowingというものを使い、無限を有限のデータにカットして、処理します。
Streaming処理するためには、下記のようにコードにします。
@JvmStatic fun main(args: Array<String>) { val options = (PipelineOptionsFactory.fromArgs(*args).withValidation().`as`(WordCountOptions::class.java)) runWordCount(options) } @JvmStatic fun runWordCount(options: WordCountOptions) { val p = Pipeline.create(options) p.apply("ReadLines", TextIO .read() .from("./src/main/kotlin/*.json") // fromで指定したファイルがないか監視する。(入力値は無限) // 10秒ごとに監視、5分間変更がなければ終了。 .watchForNewFiles(standardSeconds(10), afterTimeSinceNewOutput(standardMinutes(5))) ) // 30秒間毎にWindowingする。(無限のデータを、有限のデータにカットする) .apply(Window.into<String>(FixedWindows.of(standardSeconds(30)))) .apply(CountWords()) .apply(MapElements.via(FormatAsTextFn())) .apply<PDone>("WriteCounts", TextIO.write().to(options.output).withWindowedWrites().withNumShards(1)) p.run().waitUntilFinish() }
テストコード
Apache Beamもテストコードが書けます。 サンプルコードは、こちらです。
実行するパイプラインをTestPipelineにすることで、テストができます。
import org.apache.beam.sdk.testing.TestPipeline fun countWordsTest() { // Arrange val p: Pipeline = TestPipeline.create().enableAbandonedNodeEnforcement(false) val input: PCollection<String> = p.apply(Create.of(WORDS)).setCoder(StringUtf8Coder.of()) val output: PCollection<KV<String, Long>>? = input.apply(CountWords()) // Act p.run() // Assert PAssert.that<KV<String, Long>>(output).containsInAnyOrder(COUNTS_ARRAY) } companion object { val WORDS: List<String> = listOf( "hi there", "hi", "hi sue bob", "hi sue", "", "bob hi" ) val COUNTS_ARRAY = listOf( KV.of("hi", 5L), KV.of("there", 2L), KV.of("sue", 2L), KV.of("bob", 2L) ) }
終わりに
Apache Beamは、他にも Side inputやAdditional outputsなどがあります。 使いこなせるためにも、これからも頑張っていきます!
さて、Re:ゼロ2期を見ましょう👍
Webアプリのテスト観点を調べてまとめてみた (25選)
 最近、Property Based Test という言葉を知りました。
他にどういうテストの種類があるのか気になったので、調べてみました。
本記事は、テストの種類を列挙します。
※ 使用する技術は、私の都合上、node.jsで選んでいます。
最近、Property Based Test という言葉を知りました。
他にどういうテストの種類があるのか気になったので、調べてみました。
本記事は、テストの種類を列挙します。
※ 使用する技術は、私の都合上、node.jsで選んでいます。
- テスト観点一覧
- Cache Test
- Code Size Test
- Complexity Test
- Copy&Paste Test
- Cross Browser/Platform Test
- E2E Test
- Exception Test
- Flaky Test
- Integration Test
- Logging Test
- Monkey Test
- Multi Tenanct Test
- Mutation Test
- Chaos Test
- Performance Test
- Property Based Test
- Regression Test
- Robustness Test
- Security Test
- SEO Test
- Smoke Test
- Snapshot Test
- Static Test
- Unit Test
- Visual Regression Test
- 最後に
テスト観点一覧
Cache Test
Webアプリでは、様々なCacheが使われます。 例えば、ブラウザCache、CDN Cache、プロキシCache、バックエンドCache などなどです。 Cacheは、便利な反面、使いすぎると、どこがどうCacheしているのか迷子になってしまいます。 Webアプリでも、Cacheをテストする必要がありそうです。
Code Size Test
大きなサイズのJSライブラリを読み込むと、レスポンスタイムが悪化してしまいます。そこで、常にコードサイズを計測する必要があります。
github.com

Complexity Test
循環的複雑度(Cyclomatic complexity)は、制御文(ifやfor)の複雑さを計測します。 複雑なコードは、バグの温床になりがちなので、極力シンプルなコードを心がけたいところです。
Copy&Paste Test
Copy&Pasteは、DRYの原則に反するため、特別な理由がない限りは、してはいけません。Copy&Pasteを検出するツールがあるみたいです。
github.com

Cross Browser/Platform Test
サポートするブラウザや、プラットフォーム(iOS,Android,Desktopなど)の動作検証が必要です。 そのため、サポートするブラウザやプラットフォームの環境を準備しなければなりません。 そういう環境を手軽に使えるサービスがあったりします。
E2E Test
Webアプリを、端から端まで (End To End: E2E)を検証します。 例えば、ユーザーがWebアプリを訪れて、クリックや入力するなど、使ってみることです。 このテストは、不安定なテスト(よく失敗する)になりがちなので、安定稼働できるような取り組みが必要です。 例えば、操作する処理の抽象化や、データ固定などです。
Exception Test
正常系、準正常系、異常系などのテストが必要です。 準正常系は、システムが意図的にエラーとしているものです。例えば、フォーム入力値エラーとかです。 異常系は、システムが意図せずエラーとなるものです。例えば、Timeoutエラーとかです。
また、Javaが得意な人なら知っているであろう、検査例外や非検査例外という例外の扱い方があります。 基本的には検査例外はエラーハンドリングし、非検査例外はエラーハンドリングしない方針が良いです。
Flaky Test
不安定なテストのことを指します。これに対するアプローチ方法の1つに、Google社の資料があります。
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/45880.pdf
日本人がまとめて頂いたものが、次の資料です。 speakerdeck.com
Integration Test
Integration Testは、Unit Testのような単一機能を統合した検証になります。 定義によりますが、私は『Unit Testでは発見できないようなもの』かなと思います。 Unit Testでカバーできていなくても、他のテストで検証できていれば、Integration Testは不要になります。
Logging Test
ログ出力が適切なレベルで出力されているか検証する必要があります。 INFO, WARN, ERRORなどがルールに基づいて使い分けされているか気になります。 ログを出すことができるかどうかは、ログライブラリの検証になりますので、必要ないかもしれませんが、 意図したタイミングで、意図したログレベルで、意図したメッセージが出力されるかは、テストしても良いと思います。
Monkey Test
お猿さんがランダムにテストするような、モンキーテストです。 テストのパターン網羅が難しい場合や、パターン網羅できているけどダメ押しで、このテストをします。
github.com

Multi Tenanct Test
マルチテナントは、企業者(利用者)毎に区別した、同一のシステムを提供する方式です。 これは、企業毎にサブドメインを分けたりするため、その環境毎のテストが必要になります。
Mutation Test
テストを検証するため、突然変異テストというものがあります。 プロダクトコードを破壊することで、テストも壊れるかどうかを検証します。 もし、プロダクトコードを壊しても、テストが成功してしまうと、それは正しくテストできていません。
github.com

Chaos Test
障害を注入した際に、どういった動きになるのかを検証するテストです。
Performance Test
パフォーマンスと言っても、 CPU使用率、メモリ使用率、レスポンスタイム、RPS など様々な指標があります。 これらを計測し、SLOなどの基準値を満たせているかを検証しておく必要があります。
Property Based Test
データを半自動生成し、テストをする手法です。
Regression Test
Regression Testは、修正した内容が意図せず他の箇所に影響を及ぼしていないか(デグレーション)を確認するテストです。 このテストは幅広い意味を持つので、ここに内容されるテスト種類は多いと思います。
Robustness Test
Webアプリは、ロバストであるべきです。 何かしらWebアプリ内で障害が発生したとしても、最低限のサービスだけでも提供するのが好まれます。 もちろん、その際のHTTPステータスを200にせず、障害にあったステータスを返しましょう。
Security Test
セキュリティのテストは、どんなWebアプリでも必須になります。 セキュリティの専門家ではないので、どういうテストが必要なのかは、ここでは割愛します。
依存するパッケージ脆弱性検査には、下記のコマンドが有効です。
npm audit fix
SEO Test
Webアプリへ流入数を改善するためには、SEOは不可欠です。 lighthouseというツールでSEOスコアを見ることができるみたいです。
github.com

Smoke Test
Smoke Testは、Webアプリが最低限動作するために必要なケースを確保する検証です。 例えば、トップページへリクエストしたら、レスポンスがHTTP 200で返却されるとかです。
この最低限の動作保証がなければ、これ以上の詳細なテストができません。 個人的には、Smoke Test → E2E Test の順で進むのかなと思っています。
Snapshot Test
Webアプリへリクエストし、そのレスポンスであるHTML(スナップショット)を保存します。 このHTMLが、変更前と比較して変化がないかの検証をするのが、Snapshot testです。 リファクタリングなど、変化がない修正に対して有効です。
Static Test
Static Testは、Webアプリを動かさなくても検証できるテストです。 よくあるのが、Linter です。
HTML github.com
JS github.com
Commit github.com
Docker github.com
これらは、プルリクエストで機械的に指摘する Danger との相性が良いです。 github.com
Unit Test
単一機能をテストするUnit Testがあります。このUnit Testが全てPASSしたら、 他のテストを進めるのが一般的かなと思います。
Code Coverage
Unitテストで、どこをテストできたかのカバレッジを見ることができます。 感覚としては、全体の8割を満たしていれば良いかなと思います。
https://jestjs.io/docs/en/cli.html#--coverageboolean
実際に動作しているJSやCSSのカバレッジを収集することもできます。
speakerdeck.com puppeteer_coverage.js · GitHub
Visual Regression Test
見た目の変化を監視する必要があります。例えば、リンク切れとかがあれば、検出するべきです。
github.com

最後に
どういうテストの観点があるのか、調べたり、経験則よりざっと書いてみました。 全てをテストする必要はなく、『どういう動作の品質を担保したいか』を意識して、 取捨選択するのが良いと思います。 最後まで読んでいただき、ありがとございます。
ZoomのMeetingを自動生成するGASライブラリ zoom-meeting-creator を作った
みなさん、Zoom使っていますか? ZoomのMeetingを自動生成するGASライブラリを公開しましたので、 そのきっかけと使い方について紹介しようと思います。
きっかけ
社のSlackで次のqiitaの記事を知りました。
GASからZoomのMeetingを作れるのって、簡単なんだな〜と思いつつ、 "cronのように使いたい"というSlackのコメントがあったので、サクッと一日で作ってみました。
定期的にZoomのMeeting(IDやパスワード)を更新する会社はあるはずです。 そういう会社にとっては、このツールは、便利かもしれません。
作ったもの
これをGAS側でライブラリ追加すると使えます。 このGASでは、
- ZoomのMeetingを作成
- Slackとの連携
ができます。この機能を、GASの定期実行と組み合わせれば、"ZoomのMeeting作成をcronのように"使えるようになります。
アカウント画像一括更新ツールを作ったので、紹介と学びについて

GoogleやGithubなど、様々なサービスのプロフィール情報(画像, etc)を一括更新するツール、puppeteer-account-manager を開発しました。 開発の目的や、開発から得た知見を紹介します。
リポジトリは、こちらです。 github.com
- なんで作ったの?
- それ、Gravatarで良くない?
- どうやって作ったの?
- プロフィール画像を更新するAPIは、なかったの?
- パスワードって大丈夫?
- どのサービスが対応している?
- どんな学びがあった?
- 終わりに
なんで作ったの?
GithubやTwitter、Facebookなど、Webサービスにはプロフィール画像を登録することができます。 私の性格上、どのサービスでも、同じ画像で登録したいと考えています。
そのため、いい感じのプロフィール写真を手に入れたら、全サービスのプロフィール画像を再登録しないと気がすまなくなり、とても面倒です。 そこで、今回、その面倒さを解決したく、このツールを作りました。
それ、Gravatarで良くない?
今回の面倒さは、GravatarというWebサービスで解決できるかもしれません。
このサービスは、グローバルなプロフィール画像を提供するサービスです。 API経由で、プロフィール画像を取得できます。
しかし、次の問題があったので、却下となりました。
- gravatarが提供するプロフィール画像サイズは80px × 80px
- サービスによっては、小さすぎる
- 画像サイズを拡大することができるが、画質がよくない
- サービスによっては、小さすぎる
- gravatarが提供するプロフィール項目が固定
- 画像だけではなく、プロフィール項目も一括登録したかった
- サービスによっては、プロフィール項目がマッチしない
- 画像だけではなく、プロフィール項目も一括登録したかった
そこで、Contentful というAPIベースのCMSを使うことにしました。
Contentfulでは、自由に項目を決めることができます。 独自に作った項目 (画像や紹介文)を、API経由で取得できるため、とても便利です。
どうやって作ったの?
愚直なやり方です。 Puppeteerと呼ばれる Chromeブラウザを自動操作できるライブラリを使いました。 Chromeブラウザから、"各サービスへログインし、写真をアップロードする"処理を自動化しただけです。
プロフィール画像を更新するAPIは、なかったの?
サービスによってはあります。例えば、Twitterには、次のようなプロフィール画像を更新するAPIがあります。
ただ、全てのサービスには、そのようなAPIはありません。 APIを使って更新するのが正しい姿ですが、全サービスの実装方法の足並みを揃えるために、 Puppeteer で自動操作することにしました。
パスワードって大丈夫?
Puppeteerを動かすnodeアプリケーションと、Chromeブラウザを同一マシン内で動作するようにしました。 そのため、nodeアプリケーション実行中に、パスワードを傍受されることはありません。 また、パスワードの設定は環境変数から注入するようにしています。 Dockerコンテナで動作できるようにしているので、ローカルでも、コンテナサービスでも動かすことができます。
今後、パスワードの管理は、KeepassやLastpassのようなサービスと連携したいと思っています。
どのサービスが対応している?
対応サービスは次のとおりです。
詳しくは、 https://github.com/Silver-birder/puppeteer-account-manager/blob/master/src/index.ts をご確認下さい。
どんな学びがあった?
結構色々とハマりました。
極力 セレクタ指定したコードを書かない
Webサービスが返すHTMLは、いつもずっと変わらないことはありません。 あるidやclassのhtmlタグがずっと残り続けるとは限りません。
そこで、できる限り、セレクタを指定せずにブラウザ操作をするようにしました。 例えば、
- ボタンやリンクをクリックしてページ遷移するのではなく、目的のページへ最短で直接遷移する
- submitボタンをクリックするのではなく、エンターキーを入力する
です。こうすることで、安定した自動化ができました。
XPathが意外と使える
GoogleやMediumでは、idやclassがランダム値になっています。 そのため、単純なidやclassを指定して進めることができません。
そこで、『○○』のテキストが含まれているセレクタの指定することが、XPathでできます。 これは、助かりました。
ログインが難しいものは、無理せず諦める
Amazonのログインは、2段階認証が発生します。 テキストメッセージや、音声電話によるログインが求められ、Puppeteer単体ではどうしようもありません。
この2段階認証の機能を解除することもできますが、セキュリティ上よろしくないので、ここは無理せず諦めることにしました。
並列処理をガンガン実行する
処理速度向上のため、全サービスを Promise.allで並列処理しました。それぞれが、シークレットウィンドウで開くことで、独立して処理するようにもしました。 しかし、たまにPuppeteerが落ちてしまうことがあります。原因は、実行しているマシンのスペック(Core数)にも影響しますが、サービス側からの影響も受けたりします。 そのため、落ちても大丈夫のようにエラーハンドリングし、リトライするようにしました。
また、失敗したらどういった画面なのか知りたいので、スクリーンショットを撮るようにもしました。
Docker で実行可能に
Puppeteerに必要なモジュールをDockerに詰め込み、ログイン情報等を環境変数から外注することで、 環境非依存の実行環境ができました。そのため、Pub/SubとContainer Engine等を組み合わせれば、 ContentfulのWebfook経由で、アカウント情報を更新することができます。
終わりに
私の性格がもっと大雑把であれば、このツールを作らなかったのですが、どうしても気になって仕方がなく... (笑) 最後まで読んでいただき、ありがとうございました。
Micro Frontends を学んだすべて

Micro FrontendsというWebフロントエンドアーキテクチャがあります。 このアーキテクチャを知るために、書籍を読み、簡単なサンプルWebアプリを開発しました。 そこから学んだことをすべて議事録として残したいと思います。
- モノリシックな Webアプリケーション
- Micro Frontends とは
- Micro Frontends の良さ
- Micro Frontends の難しさ
- Micro Frontends の作る上で考えること
- Micro Frontends サンプルWebアプリ
- サンプルWebアプリで分かったこと
- 最後に
- 参考リンク
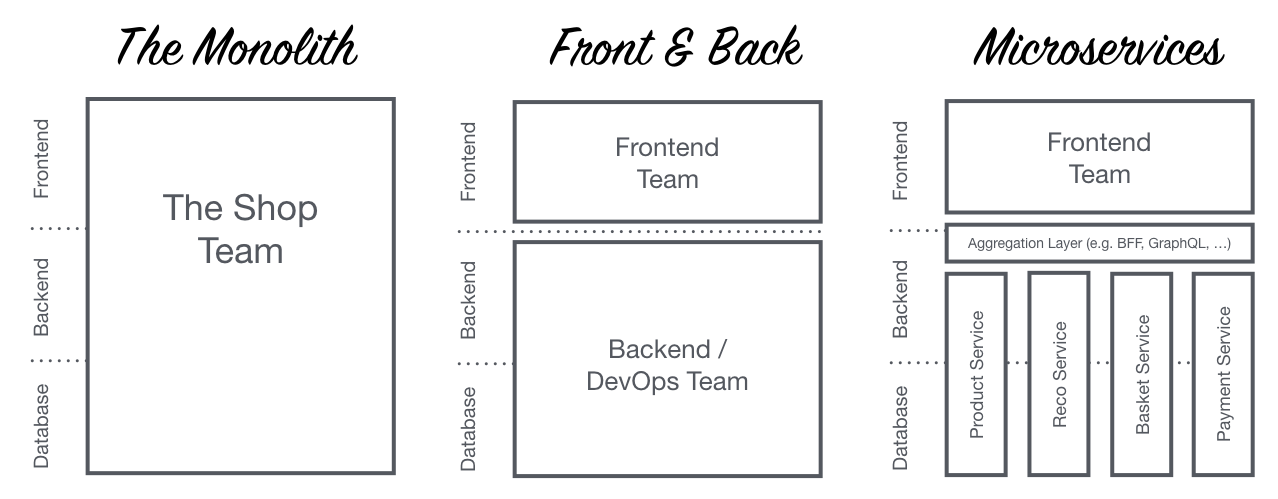
モノリシックな Webアプリケーション
マイクロサービスという考え方の多くは、バックエンドへ適用されることが一般的です。 一方で、フロントエンドは依然モノリシックなままの状態です。
ECサイトのようなWebアプリケーションでは、様々な専門知識(商品、注文、検索など)を必要とし、フロントエンド開発者の守備範囲がとても広くなってしまいます。 開発者には限界があり、いつしかトラブルシューティングに追われる日々になってしまいます。
そこで、Micro Frontendsというアーキテクチャの出番です。
Micro Frontends とは
それはマイクロサービスの考え方をフロントエンドに拡張したものです。
※ https://micro-frontends-japanese.org
要は、バックエンドだけでなく、バックエンドからフロントエンドまでをマイクロサービス化することです。
さらに詳しく知りたい方は、次のページをご参考下さい。とてもわかりやすいです。 micro-frontends-japanese.org
また、次の書籍を読むと、 www.manning.com
Amazon does not talk a lot about its internal development structure. However, there are reports that the teams who run its e-commerce site have been working like this for a long time. ...
Micro frontends are indeed quite popular in the e-commerce sector. In 2012 the Otto Group, a Germany based mail order company and one of the world’s largest e-commerce players started to split up its monolith. ...
The Swedish furniture company IKEA and Zalando, one of Europes biggest fashion retailers, moved to this model. ...
But micro frontends are also used in other industries. Spotify organizes itself in autonomous end-to-end teams they call Squads. ...
Excerpt From: Michael Geers. “Micro Frontends in Action MEAP V03.” iBooks.
という内容があります。
IKEAやZalando といったECサイトがMicro Frontendsを採用するケースが多く、公には言っていませんが、AmazonもMicro Frontendsで取り組んでいるようです。 ECサイトだけでなく、Spotifyのようなサービスにも適用されるケースがあります。
Micro Frontends の良さ
私が思う Micro Frontends から得られる最大の恩恵は、"局所化" だと思います。
フロントエンドをサービス毎(商品、注文、検索など)に分割することで
- サービスの専門性向上
- ex. 対象サービスのフロントエンドだけに集中できる
- サービスの開発速度向上
少し薄っぺらいかも知れませんが、↑のように実感しています。
※ Micro Frontendsは Webベースのアーキテクチャになります。
Micro Frontends の難しさ
ここは、まだちゃんと掘り下げれていませんが、次のようなものがあります。
- 特定チームが改善しても、チーム全体が改善しない
- ex. あるチームがwebpackのビルド時間短縮に成功しても、他のチームは影響を受けない
- ex. 全てのチームが採用しているライブラリのセキュリティパッチは、それぞれのチームが更新しなければならない
- チーム全体へ共有する仕組みを考える必要がある
- ex. デザインシステム、パフォーマンス、ナレッジ
- エッジな技術スタック採用は、チームメンバー移動を困難にする
- ex. パラダイムシフトが発生してしまう 技術スタック
Micro Frontends の作る上で考えること
フロントエンドをマイクロサービス化するということは、各サービスで HTML/CSS/JSを作ることになります。 それらのサービスを統合するサービスが重要になってきます。
大きく分けて2つの統合パターンがあります。
| 種類 | 解決手段 | メリット | デメリット |
|---|---|---|---|
| サーバーサイド統合 | SSI, ESI, Tailor, Podium | ・SEO対策上良い ・ユーザーのネットワークレイテンシーが少ない ・初回ロードパフォーマンスが優れている |
・インタラクションアプローチが不得意 |
| クライアントサイド統合 | ・Web標準 ・シャドウDOMによる堅牢な作り |
・サポートブラウザに依存する ・クライアント側のJavaScriptが有効であること |
また、これら2つの選択基準は次のようになります。
| 種類 | 選択基準 |
|---|---|
| サーバーサイド統合 | 良好な読み込みパフォーマンスと検索エンジンのランキングがプロジェクトの優先事項であること |
| クライアントサイド統合 | さまざまなチームのユーザーインターフェイスを1つの画面に統合する必要があるインタラクティブなアプリケーションを構築すること |
今回、私はサーバーサイド統合(Podium)を選択しました。 ただ、インタラクティブなアプローチも必要だったため、Hydrationを使いました。
Hydration refers to the client-side process during which Vue takes over the static HTML sent by the server and turns it into dynamic DOM that can react to client-side data changes.
※ https://ssr.vuejs.org/guide/hydration.html
Hydrationは、サーバーサイドでレンダリングした静的HTMLに、クライアントサイドの動的レンダリングができるようにするようなものです。
ちなみにWeb Componentsは、次の入門書(500円)を執筆したため、ご興味がある人は見てみて下さい。 silverbirder.booth.pm
※ クライアントサイド統合(Web Components)でも良かったのですが、私都合により却下となりました。
Micro Frontends サンプルWebアプリ
apple, banana, orangeという商品を検索するだけのサンプルWebアプリを作りました。
概要図はこちらです。
 ※
※ http://team-page.fly.dev/ 停止しました。
サンプルコードは、ここに置いています。 github.com
サービス
| サービス | 役割 | JSフレームワーク |
|---|---|---|
| team-search | 商品を検索するサービス | Vue.js |
| team-product | 商品を表示するサービス | React.js |
| team-page | サービスを統合するサービス | フレームワーク未使用 (Node.js) |
仕組み
Podium というライブラリを採用しました。
これは、フロントエンドのサービスを簡単に統合できるようなライブラリになっています。 Podium には大きく分けて3つの機能があります。
- @podium/podlet
- ページフラグメントサーバーを構築する
- ex. team-search, team-product
- @podium/layout
- Podletを集めて、ページ全体のレイアウトを構築する
- ex. team-page
- @podium/browser
- ブラウザベースの機能を提供する
- MessageBus による Podlet同士のコミュニケーション
- ex. team-search, team-product で publish/subscribe
@podium/podlet
Podletには、manifest.json と呼ばれる値を返却することが必須になっています。 menifest.jsonには、サービスのエンドポイントや、Asset(JSやCSS)のパスが明記されています。
team-search では
$ curl https://team-search.fly.dev/manifest.json | jq . { "name": "search", "version": "1.0.0", "content": "/", "fallback": "", "assets": { "js": "/search/static/fragment.js", "css": "" }, "css": [], "js": [ { "value": "/search/static/fragment.js", "async": true, "defer": true, "type": "default" } ], "proxy": {} }
というレスポンス結果になります。
@podium/layout
Layoutでは、Podletのmanifest.jsonの定義に従って fetchすることになります。
team-page では
// server.js (express) app.get(`/`, async (req, res) => { const incoming = res.locals.podium; const [searchBox] = await Promise.all([ podletSearch.fetch(incoming, {pathname: '/search/box', query: req.query}), ]); const [items] = await Promise.all([ podletProduct.fetch(incoming, {pathname: '/product/items', query: {id: searchBox.headers['x-product-items']}}) ]); res.podiumSend(` <html> <head> <title>Shop</title> ${searchBox.js.map(js => js.toHTML())} ${items.js.map(js => js.toHTML())} </head> <body> <div id="app-shell"> ${searchBox.content} ${items.content} </div> </body> </html> `); });
のようにPodletを使って、ページ全体を構築します。このようにサーバーサイドで統合しています(SSR)。 しかし、インタラクティブなアクションも必要なため、PodletからHydrateするためのjsを読み込んでいます。
また、team-searchの検索結果(x-product-items)をteam-productへ渡しているため、商品の検索結果を含めてSSRが実現できます。
@podium/browser
サーバーサイドは、podium/podlet, podium/layoutで連携できます。 クライアントサイドは、この @podium/browserのMessageBusで連携できます。
今回のサンプルWebアプリでは、次のようなユースケースに使用しています。
- ユーザーが検索ボックスにキーワードを入力する
- team-searchがキーワードから商品を検索する
- team-searchが2の結果をpublishする
- team-productが3をsubscribeし、商品を更新する
// team-search.js messageBus.publish('search', 'search.word', {items: hitItems});
// team-product.js messageBus.subscribe('search', 'search.word', event => { hydrate(<Items {...{items: event.payload.items}} />, document.querySelector('#team-product-items')); });
このようにすることで、画面更新ではなく部分更新ができました。 インタラクティブな操作も実現可能です。
状態管理, ルーティング
ここは、まだきちんと作っていませんが、次のようなコンセプトで設計するのが良いと思います。
- 状態管理
- 各サービスが状態管理する。状態は共有しない。
- 統合サービスが共通的な状態を管理する。
- ルーティング
- 各サービスがqueryを設定する。
- 統合サービスがURLパスを管理する。
その他
各サービスは、fly.io というPaaSへデプロイしています。
CDNでSSRが実行できる Edge Workerを使用しています。 これにより、SSR結果をキャッシュし、高速にレスポンスを返却できます。
ただ、サンプルWebアプリでは、全くその力を引き出せていないです...
※ 参考記事 mizchi.hatenablog.com
サンプルWebアプリで分かったこと
SSR + CSR (Hydration) が実現可能
サーバーサイド統合であっても、CSRは実現可能です。 ただし、Hydrationにはパフォーマンス面に難有りなため、このあたりは課題として残ります。 また、CSRするためのbundleしたjavascriptのsizeには注意が必要です。
例えば、次のリポジトリにある "shared_vendor_webpack_dll" のように、vendorファイルを共有することで、 javascriptのsizeを減らすといった手段があります。
また、次のリポジトリにある zalando tailorは、script loadをstreamingすることで、 全体のscript load完了時間を短縮するツールもあります。
サービス内で技術スタックを選択できる
マイクロサービスでは、よくあるメリットとして挙げられるものです。 フロントエンドでも、同様に技術スタックを自由に選択できます。
今回では、React.jsとVue.jsを使用しています。 これを Riot.jsやSvelte.jsにも切り替えることも可能です。 フロントエンド界隈では、JSフレームワークの変化が激しいので、 このメリットは大切だと思います。
ただし、Podiumのmanifest.jsonを返却しなければなりません。 今の所、Podiumに対応しているのはExpressのみなので、Expressを使用する フレームワークのみとなります。
サービス毎のフロントエンドに集中できる
検索サービスだと、検索に特化したフロントエンドのみに集中することができます。 商品サービスだと、商品の表示内容のみに集中することができます。
ただ、どうしても他サービスと連携する要件が出てきます。 これは、マイクロサービスとしての難しさだと思います。 例えば、各サービスがどのタイミングでイベント登録するのかを考える必要があります。
最後に
ECサイトのようなアプリケーションでは『商品を探しやすくする』『買いたくなるような商品を表示する』 『商品を簡単に購入できる』などフロントエンドでやるべきことが多くあります。
そういうサービスにおけるフロントエンドがモノリシックであれば、 統一性が欠けてしまったり、知らぬ間にバグを埋め込んでしまうケースが発生してしまいます。
Micro Frontendsは、このような複雑化するフロントエンドにメスを入れる良いアーキテクチャだと思います。 ただし、バックエンドにおけるマイクロサービス化による課題があるように、フロントエンドにおける マイクロサービス化にも課題はあるはずです。
日本では、Micro Frontendsの導入実績が少なく、まだまだ発展途上だと思います。 この記事が、どこかのサービスへの参考になればと思います。
最後まで読んで頂き、ありがとうございました。