CI/CDのDaggerで、GithubActionsとCircleCIにシュッと連携してみた
前々から気になっていた、CI/CD の非ベンダーロックインな Dagger というツールを試してみました。 本記事では、試した内容について共有しようと思います。
CI/CD のパイプラインを書く
Dagger では、CUE という言語を使って CI/CD のパイプラインを書きます。 公式サイトのチュートリアルから、そのまま使ってみます。 コードは、次のようなものになります。
package todoapp import ( "dagger.io/dagger" "dagger.io/dagger/core" "universe.dagger.io/netlify" "universe.dagger.io/yarn" ) dagger.#Plan & { actions: { source: core.#Source & { path: "." exclude: [ "node_modules", "build", "*.cue", "*.md", ".git", ] } build: yarn.#Script & { name: "build" source: actions.source.output } test: yarn.#Script & { name: "test" source: actions.source.output container: env: CI: "true" } deploy: netlify.#Deploy & { contents: actions.build.output site: string | *"dagger-todoapp" } } }
見慣れない構文かもしれませんが、何をやっているかはなんとなく分かるんじゃないかなと思います。
actions は、実行するものを定義していて、dagger do <action名> のようにして使います。
上の定義にあるsource: core.#Source は、 source がアクション名で、core が実行するパッケージになります。
パッケージは、次の 2 つに分類されます。
- dagger.io
- 標準機能
- core
- 標準機能
- universe.dagger.io
ローカル環境で Dagger を動かす
実際にローカルで動かしてみます。
$ dagger do test [✔] actions.test.container 11.6s [✔] actions.test.install.container.script 0.1s [✔] actions.source 0.5s [✔] actions.test.install.container 2.3s [✔] actions.test.container.script 0.1s [✔] actions.test.install.container.export 0.0s [✔] actions.test.container.export 0.2s Field Value logs """\n yarn run v1.22.17\n $ react-scripts test\n Done in 6.78s.\n\n """
特に問題なく、PASS しています。--log-format plain をつけると、実行の詳細な情報が出力されます。
$ dagger do test --log-format plain 8:06PM INFO actions.test.install.container.script._write | computing 8:06PM INFO actions.test.container._image._dag."0"._pull | computing 8:06PM INFO actions.test.install.container._image._dag."0"._pull | computing 8:06PM INFO actions.test.container.script._write | computing 8:06PM INFO actions.source | computing ...
ちなみに、actions.source が実行されているのは、actions.testがactions.sourceに依存しているためと思います。
$ NETLIFY_TOKEN=**** USER=**** dagger do deploy [✔] actions.deploy.container.script 0.2s [✔] actions.build.install.container 3.8s [✔] client.env 0.0s [✔] actions.source 0.4s [✔] actions.build.install.container.script 0.2s [✔] actions.build.container 21.0s [✔] actions.build.container.script 0.2s [✔] actions.deploy 4.8s [✔] actions.build.install.container.export 0.1s [✔] actions.build.container.export 0.1s [✔] actions.deploy.container 91.0s [✔] client.filesystem."./build".write 0.3s [✔] actions.deploy.container.export 0.0s Field Value site "****-dagger-todoapp" url "https://******-dagger-todoapp.netlify.app" deployUrl "https://xxxx--******-dagger-todoapp.netlify.app" logsUrl "https://app.netlify.com/sites/******-dagger-todoapp/deploys/xxxx"
ローカル環境で、CI/CD のパイプラインコードを動かくことができました。 次は、CI と連携したいと思います。
CircleCI で Dagger を動かす
まずは、CircleCI で Dagger を動かしてみます。 CircleCI の yml ファイルは、次の定義になります。
# .circleci/config.yml version: 2.1 jobs: install-and-run-dagger: docker: - image: cimg/base:stable steps: - checkout - setup_remote_docker: version: "20.10.14" - run: name: "Install Dagger" command: | cd /usr/local wget -O - https://dl.dagger.io/dagger/install.sh | sudo sh cd - - run: name: "Update project" command: | dagger project init dagger project update - run: name: "Testing" command: | dagger do test --log-format plain - run: name: "Deploy to Netlify" command: | dagger do deploy --log-format plain workflows: dagger-workflow: jobs: - install-and-run-dagger
CircleCI の環境変数に、NETLIFY_TOKENとUSERを設定しておきます。
この定義ファイルは、Dagger をインストールして、先程ローカル環境で動かしていた dagger do test や dagger do deploy を実行しているだけです。
この定義は、CircleCI 上で PASS します。めちゃくちゃ簡単ですね。
GithubActions で Dagger を動かす
次は、GithubActions で Dagger を動かしてみます。 GithubActions の yml ファイルは、次の定義になります。
# .github/workflows/todoapp.yml name: todoapp on: push: branches: - main jobs: dagger: runs-on: ubuntu-latest steps: - name: Clone repository uses: actions/checkout@v2 - name: Update project uses: dagger/dagger-for-github@v3 with: version: 0.2 cmds: | project init project update - name: Testing uses: dagger/dagger-for-github@v3 with: version: 0.2 cmds: | do test - name: Deploy to Netlify uses: dagger/dagger-for-github@v3 with: version: 0.2 cmds: | do deploy env: USER: ${{ secrets.USER }} NETLIFY_TOKEN: ${{ secrets.NETLIFY_TOKEN }}
ここの定義も、CircleCI の定義とほとんど一緒だと思います。
ただ、少し違うのは、GithubActions では、uses: dagger/dagger-for-github@v3 が使えるため、
cmdsが、do test や do deploy のように、daggerを書かなくて済むようになります。
GithubActions の環境変数に、NETLIFY_TOKENとUSERを設定しておきます。
そうすれば、このパイプラインも成功します。
終わりに
ローカル環境で、CI/CD のパイプラインをテストできて、それをシュッと CI サービスに連携できました。
今回は、チュートリアルのものをそのまま使っているので、テストやデプロイがシンプルな構成になっていましたが、
実務になると、より複雑な構成になると思うので、手元で確認できるのは良いものと思いました。
ただし、CUEへの学習コストがかかるため、導入する際は、そのあたりも含めて検討しましょう。
connect-webやってみた
connect-web の記事が、はてブでトレンドになっていました。気になったので、試してみました。
サンプルコードは、次のリポジトリに置いています。
前置き: gRPC と connect-web の雑な理解
RPC (Remote Procedure Call) を実現するためのプロトコルとして、gRPC があります。 このプロトコルは、ブラウザ側からは使えない(?)ため、gRPC-Web というブラウザ向けの gRPC というものを使うことになります。 その場合、ブラウザとサーバーとの間に、プロキシを建てる必要があるようです。(たぶん)
そこで、Connect という gRPC 互換の HTTP API を構築するためのライブラリ群が開発されました。 これのおかげで、プロキシを建てる必要がなく、ブラウザ側から gRPC を使うことが可能になります。
上記ページに、バックエンドは connect-go、フロントエンドは connect-web という項目があります。 connect-web は、ブラウザから RPC を動かすための小さなライブラリです。タイプセーフなライブラリなため、 型補完が効きます。 connect-go は、go で Connect のサービスを作ることができます。
そのため、フロントエンドの開発は、connect-web を使うことになります。 以降は、フロントエンドの作業を、紹介します。ちなみに、React を使います。
やってみた
フロントエンド側は、主に、次の 2 つの作業になります。
- Protocol Buffer スキーマから TypeScript ファイルを生成
- 生成された TypeScript ファイルから gRPC クライアントを実装
1. Protocol Buffer スキーマから TypeScript ファイルを生成
gRPC で通信するためのスキーマ、ProtocolBuffer スキーマが必要です。 これは、すでにあるものを使います。
具体的には、次のようなスキーマです。
syntax = "proto3";
service ElizaService {
rpc Say(SayRequest) returns (SayResponse) {}
}
message SayRequest {
string sentence = 1;
}
message SayResponse {
string sentence = 1;
}
TypeScript コードを生成するために、buf という CLI を使います。
buf で利用する、次の定義ファイルを書きます。
# buf.gen.yaml # buf.gen.yaml defines a local generation template. # For details, see https://docs.buf.build/configuration/v1/buf-gen-yaml version: v1 plugins: - name: es path: node_modules/.bin/protoc-gen-es out: gen # With target=ts, we generate TypeScript files. # Use target=js+dts to generate JavaScript and TypeScript declaration files # like remote generation does. opt: target=ts - name: connect-web path: node_modules/.bin/protoc-gen-connect-web out: gen # With target=ts, we generate TypeScript files. opt: target=ts
これは、後述する buf generate するときにどういう出力をするかの設定情報です。
codegen の yaml ファイルみたいなものかなと思います。
これを動かすために、次の module をインストールしましょう。
# plugin yarn add --dev @bufbuild/protoc-gen-connect-web @bufbuild/protoc-gen-es # runtime yarn add @bufbuild/connect-web @bufbuild/protobuf
- plugin
- runtime
次に、bufをインストールしましょう。
私は、brew でインストールしました。
brew install bufbuild/buf/buf # ref: https://github.com/bufbuild/buf#installation
では、ProtocolBuffer スキーマから TypeScript ファイルを生成しましょう。
buf generate --template buf.gen.yaml buf.build/bufbuild/eliza
成功すると、次の 2 つの TypeScript ファイルが生成されます。
- gen/buf/connect/demo/eliza/v1/eliza_connectweb.ts
- gen/buf/connect/demo/eliza/v1/eliza_pb.ts
eliza_connectweb.tsは、次のコードが含まれています。
// eliza_connectweb.ts import { SayRequest, SayResponse } from "./eliza_pb.js"; import { MethodKind } from "@bufbuild/protobuf"; export const ElizaService = { typeName: "ElizaService", methods: { say: { name: "Say", I: SayRequest, O: SayResponse, kind: MethodKind.Unary, }, }, } as const;
eliza_pb.tsは、次のコードが含まれています。
export class SayRequest extends Message<SayRequest> { /** * @generated from field: string sentence = 1; */ sentence = ""; constructor(data?: PartialMessage<SayRequest>) { super(); proto3.util.initPartial(data, this); } static readonly runtime = proto3; static readonly typeName = "buf.connect.demo.eliza.v1.SayRequest"; # ... 省略 ... } /** * SayResponse describes the sentence responded by the ELIZA program. * * @generated from message buf.connect.demo.eliza.v1.SayResponse */ export class SayResponse extends Message<SayResponse> { /** * @generated from field: string sentence = 1; */ sentence = ""; constructor(data?: PartialMessage<SayResponse>) { super(); proto3.util.initPartial(data, this); } static readonly runtime = proto3; static readonly typeName = "buf.connect.demo.eliza.v1.SayResponse"; # ... 省略 ... }
これで、準備はできました。
2. 生成された TypeScript ファイルから gRPC クライアントを実装
では、gRPC のクライアントを実装しましょう。
gRPC のクライント生成は、createPromiseClient でできます。
生成時の引数に、サービスとトランスポート(?)というものを渡す必要があります。
コードを見たほうがわかりやすいと思うので、次のコードを見てください。
// client.ts import { useMemo } from "react"; import { ServiceType } from "@bufbuild/protobuf"; import { createConnectTransport, createPromiseClient, PromiseClient, Transport, } from "@bufbuild/connect-web"; const transport = createConnectTransport({ baseUrl: "https://demo.connect.build", # バックエンド側のURL }); export function useClient<T extends ServiceType>(service: T): PromiseClient<T> { return useMemo(() => createPromiseClient(service, transport), [service]); }
このクライアントを、使ってみましょう。
// App.tsx import { createConnectTransport, Interceptor } from "@bufbuild/connect-web"; import { ElizaService } from "../gen/buf/connect/demo/eliza/v1/eliza_connectweb"; import { useClient } from "./client"; function App() { const client = useClient(ElizaService); client .say({ sentence: "hello", }) .then(({ sentence }) => { console.log(sentence); }); // ... }
このように、ProtocolBuffers の ElizaService が、型補完として使えるようになります。 良い感じです!
終わりに
意外とあっさり動いて、びっくりしました。
urqlでデータ変換(transform)してみた
GraphQL クライアントを使っていると、データ取得後にデータ変換がしたくなりませんか。私はしたくなります。 GraphQL クライアントの urql で、データ変換するのに、exchanges が使えそうだったので、それを共有します。
サンプルコードは、次のリポジトリに置いています。
https://github.com/Silver-birder/urql-exchange-transform
Exchanges
Exchanges とは、公式ページより引用します。
The Client itself doesn't actually know what to do with operations. Instead, it sends them through "exchanges". Exchanges are akin to middleware in Redux and have access to all operations and all results. Multiple exchanges are chained to process our operations and to execute logic on them, one of them being the fetchExchange, which as the name implies sends our requests to our API.
ざっくりいうと、GraphQL の通信フロー(リクエスト/レスポンス)にアクセスできる機構です。レスポンスにアクセスできるため、 データ変換もできます。exchanges にデータ変換を一手に引き受けるため、useQuery などクエリ発行する側で、何度も変換コードを書く必要がなくなります。
Transform exchange
サンプルコードを紹介する前に、GraphQL のデータソースとして Pokemon を使います。 URL とクエリは、次のものを使います。
query Pokemons { pokemons { id name } }
データ変換は、次のようなコードを書きます。
map の部分が、実際のデータ変換になります。今回は、name をtoLowerCaseしています。
export const transformExchange = ({ forward }) => { return (ops$) => pipe( ops$, forward, // Sample transform code map((result) => { const { data } = result; if (!data || !data.pokemons) { return result; } const { pokemons } = data; result.data.pokemons = pokemons.map((pokemon) => { pokemon["name"] = pokemon.name.toLowerCase(); return pokemon; }); return result; }) ); };
transformExchange 関数を urql のクライアントに渡します。
import { createClient, fetchExchange } from "urql"; import { transformExchange } from "./transformExchange"; client = createClient({ url: "https://trygql.formidable.dev/graphql/basic-pokedex", exchanges: [transformExchange, fetchExchange], });
exchanges は、何も指定しない場合、defaultExchangesが使われます。今回、必要最低限の説明のために、defaultExchangesの内の fetchExchange だけ使いました。
あとは、次のコードのように useQuery でデータ取得すれば良いです。データ取得後のデータは、データ変換された結果になっています。
import { useQuery } from "urql"; const PokemonsQuery = ` query Pokemons { pokemons { id name } } `; export const Pokemons = () => { const [result] = useQuery({ query: PokemonsQuery, }); const { data, fetching, error } = result; if (fetching) return <p>Loading...</p>; if (error) return <p>Oh no... {error.message}</p>; return ( <ul> {data.pokemons.map((pokemon) => ( <li key={pokemon.id}>{pokemon.name}</li> ))} </ul> ); };
pokemon.name が toLowerCase されています。
終わりに
urql の exchanges って、wonkaというReason言語で書かれたライブラリに依存しているので、調査するのが少し苦労しました。
GraphQLの歴史
GraphQL を業務で使い始めました。 いつものように、GraphQL の歴史が気になったので、調べてみました。
参考資料
GraphQL の共同開発者で、GraphQL Foundation エグゼクティブディレクターである Lee Byron さんから、GraphQL の歴史について、紹介されています。
次の資料も参考になります。
- https://dev.to/tamerlang/a-brief-history-of-graphql-2jhd
- https://levelup.gitconnected.com/what-is-graphql-87fc7687b042
GraphQL が生まれる前
GraphQL が生まれる前の歴史を、簡単に要約しました。
| 年 | 要約 |
|---|---|
| 2004 | ソーシャルメディア Web サイト「Thefacebook」が公開され、後に FaceBook になりました |
| 2007 | iPhone の登場により、モバイルが急速に普及し始めましたが、FaceBook は HTML5 に賭けすぎて失敗しました |
| 2012 | FaceBook はモバイル(iOS) のニュースフィードを REST API で開発し始めました |
REST API での開発における 3 つの課題
REST API で開発を進めていくと、次の 3 つの課題を抱えてしまいました。
- Slow on network
- Fragile client/server relationship
- API の変更を、クライアントコードに慎重に引き継がなければ、クラッシュしてしまいました
- Tedious code & process
これらの課題を解決すべく、FaceBook は、スーパーグラフと呼ばれるプロトタイプを開発しました。 そのベストプラクティスを集めたものが、GraphQL となりました。
例:複数のリクエストを何度も往復する
複数のリクエストをする例が、次のページに書いています。
例として、ユーザー情報、ユーザーが投稿したコンテンツ、ユーザーのフォロワーという 3 つの情報を取得するケースです。
REST API の場合は、次の画像のように 3 往復することになります。

GraphQL の場合は、1 回の往復だけでデータが取得できます。

REST API から GraphQL へ
REST API から、GraphQL に切り替えた結果、次の 3 つのメリットを享受することができました。
- Fast on network
- 必要なものだけを記述できるため、1 回のリクエストで十分です
- Robust static types
- どのようなデータが利用可能か、どのような型か、クライアントは知ることができます
- Empowering client evolution
- レスポンスのフォーマットはクライアントが制御できます。そのため、サーバーサイドはシンプルになり、メンテナンスも容易になります
- 古いフィールドを非推奨とし、機能は継続できます。この後方互換性によりバージョニング管理が不要になります
3 つの課題を 改めて考える
REST API の 3 つの課題を、2022 年の今、改めて考えてみます。
- Slow on network
- Fragile client/server relationship
- Tedious code & process
- スキーマ駆動な開発で、問題解決できるのではないか
簡単に書いていますが、3 つの課題は、もっと深い・困難な話だったのかもしれません。 ですが、今の時代で考えてみると、GraphQL を使うユースケースは、エッジケースなのかなと思ってしまいました。 本件の課題の根幹の 1 つは、ニュースフィードにおけるデータ構造の複雑さ(再帰的,ネスト)じゃないのかなと想像していました。
参考リンク
- https://www.apollographql.com/blog/graphql/basics/why-use-graphql/
- https://wundergraph.com/blog/why_not_use_graphql
GraphQL の魅力
データの取捨選択
GraphQL の必要なデータを記述できる機能は、魅力的と思います。 従来の REST API の開発設計では、次のようなパターンを業務で経験してきました。
- レスポンスデータのバリエーションをグループ分けするクエリパラメータ Response group
- Response group
- small
- 最小セット
- middle
- small と large の中間
- large
- 全てのフィールド
- small
- Response group
Response group での開発で、特に大きな課題と感じたことはありませんでした。 データの取捨選択は、API のスケールのしやすさがメリットのように思います。
データの階層構造
GraphQL は、リクエスト・レスポンスのデータに、階層構造を表せます。 これも、魅力的です。
従来の REST API では、リクエストのクエリパラメータは、フラットな形で送るしかありませんでした。リクエストボディを使って、JSON を送るという手段もあります。(まあ、これが GraphQL なんですが)
REST API のリクエストに、階層構造を表せるのは、データの関係性を示せるため、柔軟性が高く良さそうです。
ただ、個人的な違和感
データ参照も POST
REST API は、参照なら HTTP GET、更新なら HTTP POST を使うのが当たり前です。 GraphQL は、参照も更新も HTTP POST を使います。これに違和感があります。 query は、HTTP GET、mutation は、HTTP POST で使い分けできるようにしたいです。
終わりに
GraphQL の歴史を簡単に紹介しました。 まだそんなに使ったことがないので、良さ・悪さをしっかり理解していきたいと思います。
JavaScriptのdebuggerを使ってデバッグしよう (Browser/Node.js/Jest)
JavaScript の標準機能 debugger を使って、デバッグをしましょう。
標準機能なので、React などのライブラリでも使えます。
Browser
次の HTML ファイルを Chrome で開きます。
<!-- index.html --> <button>Button</button> <script> document.querySelector("button").addEventListener("click", () => { debugger; alert("Hello World"); }); </script>
開いたページで、DevTools も開いておきます。 その状態で、Button をクリックしましょう。
そうすると、次の画像のようになります。

debuggerと書いた箇所で、処理が停止されます。
そのブレークポイントから、ステップイン、ステップアウト、ステップオーバーといった操作ができます。
Console タブで、変数や関数などの実行結果を確認できます。
このように、簡単にデバッグができるようになります。
Node.js
Node.js でも、同様に debugger が使えます。
次の JavaScript コードを用意します。
// main.js debugger; console.log("Hello World");
このファイルを次のコマンドで実行します。
node --inspect-brk main.js
実行すると、次の画像のような出力になります。

その後、Chrome から chrome://inspect にアクセスしてください。
アクセスすると、次の画像の画面になります。

Open dedicated DevTools for Node を Click したら、次の画像のようになります。

そうです、さきほどと同じように、debugger の箇所で、処理が停止されます。
簡単ですね。
Jest
テストフレームワークの Jest も、同じように debugger が使えます。
次のテストコードを用意します。
// main.test.js test("1 equal 1", () => { debugger; expect(1).toBe(1); });
このファイルに対して、次のコマンドを実行します。
# mac node --inspect-brk node_modules/.bin/jest --runInBand main.test.js # windows node --inspect-brk ./node_modules/jest/bin/jest.js --runInBand main.test.js
実行すると、次の画像のような出力になります。

また、同じく Chrome からchrome://inspect にアクセスすると、同様にデバッグできます。

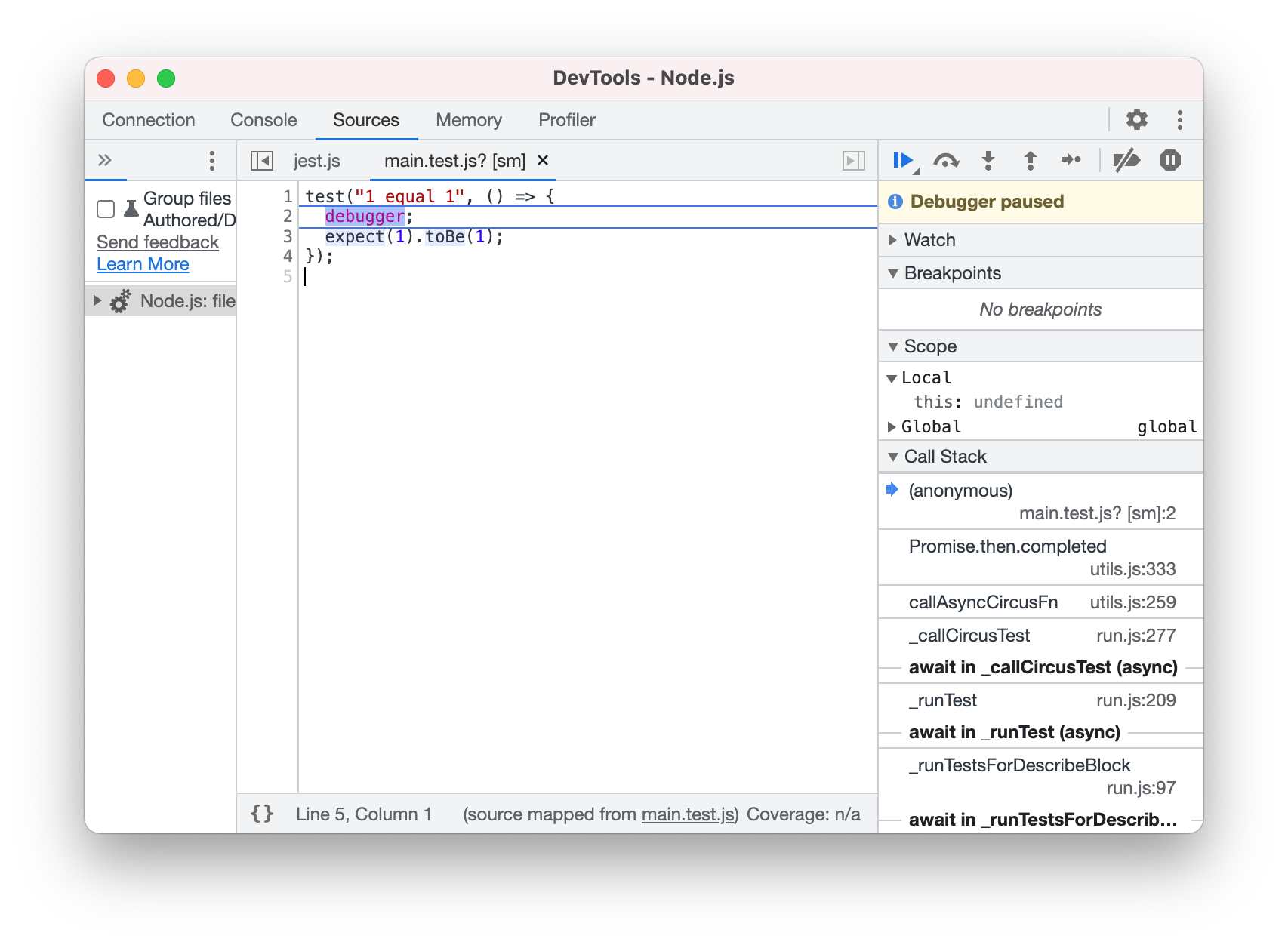
Browser,Node.js と同じ使い方になります。 わかりやすいですね。
終わりに
IDE やエディタでデバッグ設定することもできますが、こちらの方が断然楽ですね。