Micro Frontends を調べたすべて

Micro Frontendsに関わる記事を100件以上読みました(参考記事に記載しています)。そこから得たMicro Frontendsについてこの投稿に記録します。 また、調査メモについて、次のリポジトリに残しています。 github.com
発端
実績企業
- Airbnb
- Allegro
- Amazon
- Beamery
- Bit.dev
- BuzzFeed
- CircleCI
- DAZN
- Elsevier
- Entando
- Fiverr
- Hello Fresh
- IKEA
- Klarna
- Microsoft
- Open Table
- OpenMRS
- Otto
- Paypal
- SAP
- Sixt
- Skyscanner
- Smapiot
- Spotify
- Starbucks
- Thalia
- Upwork
- Zalando
- ZEISS
Pros/Cons
Pros
| 観点 | 内容 |
|---|---|
| 独立性 | ・任意のテクノロジーと任意のチームで開発可能 |
| 展開 | ・特定の機能をエンドツーエンド(バック、フロント、デプロイ)で確実に実行可能 |
| 俊敏性 | ・特定のドメインについて最高の知識を持つチーム間で作業を分散すると、リリースプロセスが確実にスピードアップして簡素化される。 ・フロントエンドとリリースが小さいということは、リグレッションテストの表面がはるかに小さいことを意味する。リリースごとの変更は少なく、理論的にはテストに費やす時間を短縮できる。 ・フロントエンドのアップグレード/変更にはコストが小さくなる |
Cons
| 観点 | 内容 |
|---|---|
| 独立性 | ・独立できず、相互接続しているチームが存在しがち ・多くの機能で複数のマイクロフロントエンドにまたがる変更が必要になり、独立性や自律性が低下 ・ライブラリを共有すること自体は問題ないが、不適切な分割によって作成された任意の境界を回避するための包括的な場所として使用すると、問題が発生する。 ・コンポーネント間の通信の構築は、実装と維持が困難であるだけでなく、コンポーネントの独立性が取り除かれる ・横断的関心事への変更ですべてのマイクロフロントエンドを変更することは、独立性が低下する |
| 展開 | ・より大きな機能の部分的な実装が含まれているため、個別にリリースできない ・サイト全体の CI / CD プロセス |
| 俊敏性 | ・重複作業が発生する ・検出可能性が低下した結果、一部の標準コンポーネントを共有できず、個別のフロントエンド間で実装が重複してしまう。 ・共有キャッシュがないと、各コンポーネントは独自のデータセットをプルダウンする必要があり、大量の重複呼び出しが発生する。 |
| パフォーマンス | ・マイクロフロントエンドの実装が不適切な場合、パフォーマンスが低下する可能性がある。 |
統合パターン
| 統合 | 選択基準 | 技術 |
|---|---|---|
| サーバーサイド統合 | 良好な読み込みパフォーマンスと検索エンジンのランキングがプロジェクトの優先事項であること | ・Podium ・Ara-Framework ・Tailor ・Micromono ・PuzzleJS ・namecheap/ilc |
| エッジサイド統合 | サーバーサイド統合と同じ | ・Varnish EDI ・Edge Worker CDN ・ Akamai ・ Cloudfront ・ Fastly ・CloudFlare ・ Fly.io |
| クライアント統合 | さまざまなチームのユーザーインターフェイスを 1 つの画面に統合する必要があるインタラクティブなアプリケーションを構築すること | ・Ajax ・Iframe ・Web Components ・Luigi ・Single-Spa ・FrintJS ・Hinclude ・Mashroom |
| ビルド時統合 | 他の統合が非常に複雑に思われる場合に、 小さなプロジェクト(3 チーム以下)にのみ使用すること |
・ Bit.dev ・ Open Components ・ Piral |
機能
コミュニケーション
developer.mozilla.org github.com
データ共有
- ストレージ
- URL
- Cookie
- Local Storage/Session Storage
モジュール共有
- webpack
webpack.js.org webpack.js.org webpack.js.org
ルーティング
Vaddin router vaadin.com
キャッシュ
developer.mozilla.org developer.mozilla.org
認証
- JWT
計測
- Google Analytics
- Navigation Timing API
- Resource Timing API
- High Resolution Time API
- User Timing API
- Frame Timing API
- Server Timing API
- Performance Observer
Real User Monitoring
- SpeedCurve
- Catchpoint
- New Relic
- Boomerang.js
- Parfume.js
- sitespeed.io
Synthetics Monitoring
- Lighthouse
- WebpageTest
Proxy
コンポジションプロキシ。テンプレートを組み合わせる。 github.com
アクセス履歴
分割ポリシー
フロントエンドを分割する方針について
- 水平分割
- 画面内にある要素で分割
- ビジネス上の機能
- 垂直分割
- 画面毎に分割
Webサイト⇔Webアプリ
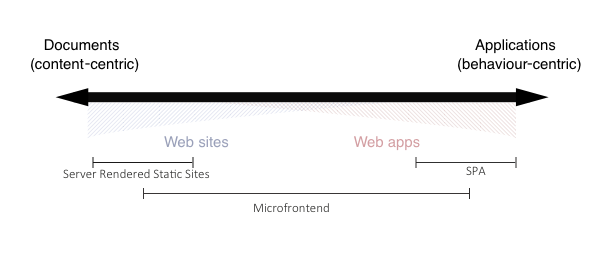
※ Microfrontends: An approach to building Scalable Web Apps
マイクロフロントエンドは、かなりのオーバーラップがあるバンドの中央部分の大部分に最も適しています。バンドの両極端に該当するプロジェクトにマイクロフロントエンドアーキテクチャを実装しようとすると、生産性に反するそうです。
リポジトリ
| パターン | Pros | Cons | 技術 |
|---|---|---|---|
| モノリポ | コードベース全体に簡単にアクセスできる。 (検出可能性が高い) |
モノリポジトリは、特に大規模なチームで作業しているときに、 動作が遅くなる傾向があり、バージョン管理下のコミットとファイルの数が増加する。 |
・nx.dev ・lerna |
| マルチリポ | ・マルチリポジトリは、非常に大規模なプロジェクトと それに取り組む非常に大規模なチームがある場合に最適。 |
マルチリポジトリ環境では、各マイクロアプリを 個別にビルドする必要がある。 |
他アーキテクチャ
| アーキテクチャ名 | 関係リンク |
|---|---|
| Modular Monolith | ・Deconstructing the Monolith – Shopify Engineering ・kgrzybek/modular-monolith-with-ddd |
| Enterprise Architecture (Clean Architecture) | ・Building an Enterprise Application with Vue ・soloschenko-grigoriy/vue-vuex-ts |
| Jam Stack | Jam Stack |
| App Shell | App Shell モデル |
書籍
参考記事
- https://blog.bitsrc.io/communication-between-micro-frontends-67a745c6cfbe
- https://medium.com/swlh/luigi-micro-fronteds-orchestrator-8c0eca710151
- https://medium.com/swlh/micro-frontends-in-action-221d4ed81c35
- https://medium.com/swlh/problems-with-micro-frontends-8a8fc32a7d58
- https://levelup.gitconnected.com/podium-easy-server-side-micro-frontends-385f3a4cd346
- https://levelup.gitconnected.com/micro-frontend-curry-506b98a4cfc0
- https://medium.com/javascript-in-plain-english/demystify-micro-frontends-using-component-libraries-53aa9a33cf5b
- https://medium.com/@areai51/microfrontends-an-approach-to-building-scalable-web-apps-e8678e2acdd6
- https://medium.com/@shubhranshutiwari07/micro-frontend-microfe-is-superman-part-1-basic-understanding-architectures-21970d3fc218
- https://medium.com/better-programming/5-steps-to-turn-a-random-react-application-into-a-micro-frontend-946718c147e7
- https://medium.com/@lucamezzalira/micro-frontends-decisions-framework-ebcd22256513
- https://medium.com/hacking-talent/two-years-of-micro-frontends-a-retrospective-522526f76df4
- https://medium.com/@sagiv.bengiat/integrate-react-with-other-applications-and-frameworks-94d443e3cc3f
- https://medium.com/js-dojo/serverless-micro-frontends-using-vue-js-aws-lambda-and-hypernova-835d6f2b3bc9
- https://medium.com/swlh/micro-frontend-using-web-components-e9faacfc101b
- https://medium.com/@tomsoderlund/micro-frontends-a-microservice-approach-to-front-end-web-development-f325ebdadc16
- https://medium.com/@PepsRyuu/micro-frontends-341defa8d1d4
- https://medium.com/hepsiburadatech/hepsiburada-micro-frontend-d%C3%B6n%C3%BC%C5%9F%C3%BCm%C3%BC-4c2f26b8dcae
- https://medium.com/javascript-in-plain-english/create-micro-frontends-using-web-components-with-support-for-angular-and-react-2d6db18f557a
- https://medium.com/hackernoon/understanding-micro-frontends-b1c11585a297
- https://medium.com/javascript-in-plain-english/micro-frontends-made-easy-e49acceea536
- https://itnext.io/building-micro-frontend-applications-with-angular-elements-34483da08bcb
- https://blog.pragmatists.com/independent-micro-frontends-with-single-spa-library-a829012dc5be
- https://blog.bitsrc.io/state-of-micro-frontends-9c0c604ed13a
- https://medium.com/stepstone-tech/microfrontends-extending-service-oriented-architecture-to-frontend-development-part-1-120b71c87b68
- https://medium.com/bb-tutorials-and-thoughts/6-different-ways-to-implement-micro-frontends-with-angular-298bc8d79f6b
- https://medium.com/@benjamin.d.johnson/exploring-micro-frontends-87a120b3f71c
- https://medium.com/hacking-talent/using-micro-frontends-to-permanently-solve-the-legacy-javascript-problem-5fba18b0ceac
- https://medium.com/dazn-tech/micro-frontends-the-future-of-frontend-architectures-5867ceded39a
- https://medium.com/swlh/build-micro-frontends-using-angular-elements-the-beginners-guide-75ffeae61b58
- https://medium.com/dazn-tech/adopting-a-micro-frontends-architecture-e283e6a3c4f3
- https://codeburst.io/breaking-a-large-angular-app-into-microfrontends-fb8f985d549f
- https://medium.com/dazn-tech/orchestrating-micro-frontends-a5d2674cbf33
- https://tech.buzzfeed.com/micro-frontends-at-buzzfeed-b8754b31d178
- https://blog.bitsrc.io/serverless-microfrontends-in-aws-999450ed3795
- https://medium.com/dazn-tech/identifying-micro-frontends-in-our-applications-4b4995f39257
- https://medium.com/@gilfink/avoiding-the-framework-catholic-wedding-using-stencil-compiler-3c2aa55bcaca
- https://medium.com/@lucamezzalira/building-micro-frontends-the-book-a2b531d0279a
- https://blog.bitsrc.io/tools-and-practices-for-microfrontends-dab0283393f2
- https://medium.com/better-programming/thoughts-about-micro-frontends-in-2020-dd95eb7216f
- https://medium.com/@rangleio/five-things-to-consider-before-choosing-micro-frontends-f685e71bdd76
- https://blog.bitsrc.io/how-we-achieved-smooth-navigation-across-micro-frontends-42130577924d
- https://eng.collectivehealth.com/gracefully-scaling-web-applications-with-micro-frontends-part-i-162b1e529074
- https://eng.collectivehealth.com/gracefully-scaling-web-applications-with-micro-frontends-part-ii-8fa730d05b14
- https://medium.com/bb-tutorials-and-thoughts/should-we-frameworks-for-micro-frontends-35f9f15b7821
- https://medium.com/javascript-in-plain-english/microfrontends-bringing-javascript-frameworks-together-react-angular-vue-etc-5d401cb0072b
- https://medium.com/@rchaves/building-microfrontends-part-i-creating-small-apps-710d709b48b7
- https://blog.bitsrc.io/6-patterns-for-microfrontends-347ae0017ec0
- https://medium.jonasbandi.net/frontend-monoliths-run-if-you-can-voxxed-day-zuerich-2019-d8d714ff361a
- https://medium.com/@gilfink/why-im-betting-on-web-components-and-you-should-think-about-using-them-too-8629396e27a
- https://medium.com/@ScriptedAlchemy/webpack-5-module-federation-stitching-two-simple-bundles-together-fe4e6a069716
- https://medium.com/passionate-people/my-experience-using-micro-frontends-e99a1ad6ed32
- https://engineering.contaazul.com/evolving-an-angularjs-application-using-microfrontends-2bbcac9c023a
- https://blog.bitsrc.io/11-popular-misconceptions-about-micro-frontends-d5daecc92efb
- https://medium.com/js-dojo/micro-frontends-using-vue-js-react-js-and-hypernova-af606a774602
- https://medium.com/linedevth/micro-frontends-the-new-era-of-front-end-edge-technology-cb981ad26eae
- https://blog.bitsrc.io/sharing-dependencies-in-micro-frontends-9da142296a2b
- https://medium.com/@pyaesonenyein/micro-frontends-part-one-95ea3d939bc6
- https://medium.com/outbrain-engineering/micro-front-ends-doing-it-angular-style-part-1-219c842fd02e
- https://levelup.gitconnected.com/brief-introduction-to-micro-frontends-architecture-ec928c587727
- https://itnext.io/prototyping-micro-frontends-d03397c5f770
- https://blog.bitsrc.io/mini-web-apps-a-bounded-context-for-microfrontends-with-microservices-f1482af9276f
- https://medium.com/trendyol-tech/micro-frontends-how-it-changed-our-development-process-a5cf667356da
- https://medium.embengineering.com/micro-front-end-and-web-components-ce6ae87c3b7f
- https://medium.com/@witek1902/ui-in-microservices-world-micro-frontends-pattern-and-web-components-23607a569363
- https://medium.com/stepstone-tech/microfrontends-part-2-integration-and-communication-3385bc242673
- https://blog.bitsrc.io/building-react-microfrontends-using-piral-c26eb206310e
- https://medium.com/js-dojo/implementing-microfrontends-in-nuxt-js-using-svelte-and-ara-framework-8c06b683472c
- https://itnext.io/implementing-microfrontends-in-gatsbyjs-using-ara-framework-a95ee79cc0e7
- https://itnext.io/strangling-a-monolith-to-micro-frontends-decoupling-presentation-layer-18a33ddf591b
- https://itnext.io/page-building-using-micro-frontends-c13c157958c8
- https://medium.com/notonlycss/micro-frontends-architecture-1407092403d5
- https://medium.com/soluto-nashville/not-so-micro-frontends-building-a-reverse-proxy-f41ab5cde81c
- https://medium.com/@armand1m_/why-micro-frontends-might-not-work-for-you-5a810b4687b0
- https://medium.embengineering.com/micro-front-ends-webpack-manifest-b05fc63a0d53
- https://medium.com/better-programming/you-dont-have-to-lose-optimization-for-micro-frontends-60a63d5f94fe
- https://medium.com/wix-engineering/3-ways-micro-frontends-could-improve-your-life-dev-velocity-and-product-97ff611881b5
- https://medium.com/oracledevs/microservice-approach-for-web-development-micro-frontends-1cba93d85021
- https://medium.com/@miki.lombi/micro-frontends-from-the-00s-to-20s-19b37efece6d
- https://medium.com/@soroushchehresa/deep-dive-into-the-micro-frontends-approach-c2ba1e5cd689
- https://medium.embengineering.com/micro-front-ends-server-side-rendering-2b515220a56e
- https://medium.com/wehkamp-techblog/sharing-server-code-between-micro-sites-4f23359101e5
- https://medium.com/@mikkanthrope/sso-with-jwt-and-react-micro-frontends-811f0fcc4121
- https://itnext.io/the-micro-frontends-journey-tech-agnostic-principle-b61414b19505
- https://medium.com/@singh.architsinghaim/micro-front-ends-dc105f5c0fea
- https://medium.embengineering.com/micro-front-ends-76171c02ab17
- https://medium.com/codingtown/micro-frontends-mystery-8b51b6e2f7f9
- https://medium.com/rangle-io/micro-frontends-and-the-rise-of-federated-applications-265171bcb346
- https://medium.com/@felipegaiacharly/the-micro-frontends-journey-tech-agnostic-principle-b61414b19505
- https://medium.com/better-practices/how-postman-engineering-does-microservices-aa026a3d682d
- https://medium.com/ergonode/create-your-own-vue-micro-frontend-architecture-with-vuems-library-f054233b97cb
- https://blog.bitsrc.io/how-to-develop-microfrontends-using-react-step-by-step-guide-47ebb479cacd
- https://medium.com/jit-team/microfrontends-should-i-care-12b871f70fa3
- https://medium.com/mailup-group-tech-blog/micro-frontends-in-the-mailup-console-82a81e712cfe
- https://towardsdatascience.com/looking-beyond-the-hype-is-modular-monolithic-software-architecture-really-dead-e386191610f8
- https://medium.com/swlh/developing-and-deploying-micro-frontends-with-single-spa-c8b49f2a1b1d
- https://levelup.gitconnected.com/easy-svelte-micro-frontends-with-podium-34aa949bed02
- https://medium.com/swlh/react-vue-svelte-on-one-page-with-micro-frontends-f740b3ee6979
- https://blog.bitsrc.io/using-es-modules-with-dynamic-imports-to-implement-micro-frontends-7c840a38890e
- https://medium.com/@jh.rossa/micro-frontend-federation-today-and-tomorrow-4eda3ab69409
- https://medium.com/design-and-tech-co/modular-monoliths-a-gateway-to-microservices-946f2cbdf382
- https://medium.com/swlh/implementing-micro-frontends-using-react-8d23b7e0a687
- https://medium.com/javascript-in-plain-english/javascript-monorepo-with-lerna-5729d6242302
- https://levelup.gitconnected.com/a-micro-frontend-solution-for-react-1914b19663b
- https://medium.com/@lucamezzalira/i-dont-understand-micro-frontends-88f7304799a9
- https://floqast.com/engineering-blog/post/implementing-a-micro-frontend-architecture-with-react/
- https://blog.bitsrc.io/how-we-build-micro-front-ends-d3eeeac0acfc
- https://medium.com/upwork-engineering/modernizing-upwork-with-micro-frontends-d5be5ec1d9a
- https://blog.bitsrc.io/implementing-micro-front-end-with-single-spa-and-react-eeb4364100f
- https://www.redhat.com/en/blog/5-benefits-using-micro-frontends-build-process-driven-applications
- https://medium.com/swlh/cross-app-bundling-a-different-approach-for-micro-frontends-e4f212b6a9a
- https://www.esentri.com/composing-micro-frontends-server-side
- https://dev.to/dabit3/building-micro-frontends-with-react-vue-and-single-spa-52op
- https://dev.to/florianrappl/11-popular-misconceptions-about-micro-frontends-463p
- https://dev.to/rsschouwenaar/thoughts-about-micro-frontends-in-2020-39ed
- https://dev.to/onerzafer/understanding-micro-frontends-1ied
- https://dev.to/aregee/breaking-down-the-last-monolith-micro-frontends-hd4
- https://dev.to/thejoin95/micro-frontends-from-the-00s-to-20s-5a2
- https://dev.to/florianrappl/communication-between-micro-frontends-41fe
- https://dev.to/phodal/micro-frontend-architecture-in-action-4n60
- https://dev.to/jondearaujo/the-approaches-and-challenges-of-micro-frontends-a-theoretical-introduction-176
- https://dev.to/scriptedalchemy/micro-frontend-architecture-replacing-a-monolith-from-the-inside-out-3ali
- https://dev.to/abhinavnigam2207/an-approach-to-micro-frontend-architecture-mvp-with-nextjs-2l84
- https://dev.to/jamesmh/using-micro-uis-to-extend-legacy-web-applications-166
- https://dev.to/jonisar/11-must-know-frontend-trends-for-2020-13e1
- https://dev.to/manfredsteyer/6-steps-to-your-angular-based-microfrontend-shell-1nei
- https://dev.to/coroutinedispatcher/working-on-modularising-android-app-314c
- https://dev.to/remast/my-software-architecture-resources-g38
- https://dev.to/open-wc/open-wc-scoped-elements-3e47
- https://medium.com/cdiscount-engineering/microservices-frontend-module-federation-an-handsome-promise-3b309944c215
- https://medium.com/@infoxicator/what-is-holocron-224255625241
- https://medium.com/paypal-engineering/how-micro-frontend-has-changed-our-team-dynamic-ba2f01597f48
- https://dev.to/kleeut/how-do-you-share-authentication-in-micro-frontends-5glc
- https://github.com/ChristianUlbrich/awesome-microfrontends
- https://github.com/rajasegar/awesome-micro-frontends
- https://github.com/MPankajArun/awesome-micro-frontends
- https://github.com/phodal/microfrontends
- https://martinfowler.com/articles/micro-frontends.html
- https://thenewstack.io/microfrontends-the-benefits-of-microservices-for-client-side-development
- https://allegro.tech/2016/03/Managing-Frontend-in-the-microservices-architecture.html
- https://engineering.hellofresh.com/front-end-microservices-at-hellofresh-23978a611b87
- http://tech.opentable.co.uk/blog/2016/04/27/opencomponents-microservices-in-the-front-end-world/
- http://tech.opentable.co.uk/blog/2015/02/09/dismantling-the-monolith-microsites-at-opentable/
- https://medium.com/@matteofigus/5-years-of-opencomponents-3114e6d6a35b
- https://blog.senacor.com/microfrontends/
- https://www.infoq.com/news/2018/08/experiences-micro-frontends/
- https://dzone.com/articles/building-micro-frontends-with-single-spa-and-react
- https://www.agilechamps.com/microservices-to-micro-frontends/
- https://gustafnk.github.io/microservice-websites/
- https://hub.packtpub.com/what-micro-frontend/
- https://www.thoughtworks.com/de/radar/techniques/micro-frontends
- http://blog.wolksoftware.com/microlibraries-the-future-of-web-development
- https://xebia.com/blog/the-monolithic-frontend-in-the-microservices-architecture/
- https://x-team.com/blog/micro-frontend/
- https://menelaos.dev/devweek-sf-2020/
- https://www.infoq.com/news/2020/07/microfrontends-vue-yoav-yanovski/
- https://www.infoq.com/articles/microfrontends-business-needs
- https://www.infoq.com/articles/architecture-trends-2020/
- https://www.infoq.com/news/2018/08/experiences-micro-frontends/
- https://www.infoq.com/news/2020/01/strategies-micro-frontends/
- https://speakerdeck.com/kimh/k8stotraefikdetukurumaikurohurontoendo
Zalando tailor で Micro Frontends with ( LitElement & etcetera)
 Photo by Kenny Luo on Unsplash
Photo by Kenny Luo on Unsplash
Zalando社が開発したTailorを使って、サンプルWebアプリをMicro Frontendsで構築してみました。Tailorはサーバーサイドで統合するアーキテクチャです。クライアントサイドは、Web Componentsで作られているLit Elementを使って統合しました。どういった内容か、ここに投稿しようと思います。
作ったリポジトリは、下記に残しています。 github.com
全体構成

ざっくり説明すると、HTMLからTailorに対してフラグメント(コンポーネント)を取得・返却するようにします。各フラグメントは、LitElementでWebComponentsを定義させたJavascriptを指します。フラグメントを読み込むだけで、カスタムエレメントを使えるようになります。
Tailor
A streaming layout service for front-end microservices
tailorは、ストリーミングレイアウトサービスというだけあって、fragmentのloadをストリーミングするそうです。(こちらのライブラリは、FacebookのBigPipe に影響されたそう)
まず、tailor.jsのHTMLテンプレートは次のとおりです。
templates/index.html
<body> <div id="outlet"></div> <fragment src="http://localhost:7000" defer></fragment> <fragment src="http://localhost:8000" defer></fragment> <fragment src="http://localhost:9000" defer></fragment> </body>
これらのfragmentの取得は、tailor.jsを経由します。
tailor.js
const http = require('http')
const Tailor = require('node-tailor')
const tailor = new Tailor({
templatesPath: __dirname + '/templates'
})
http
.createServer((req, res) => {
req.headers['x-request-uri'] = req.url
req.url = '/index'
tailor.requestHandler(req, res)
})
.listen(8080)
x-request-uriは、後ろのフラグメントにURLを引き継ぐためのようです。 そして、フラグメントサーバーは、次のとおりです。
fragments.js
const http = require('http')
const url = require('url')
const fs = require('fs')
const server = http.createServer((req, res) => {
const pathname = url.parse(req.url).pathname
const jsHeader = { 'Content-Type': 'application/javascript' }
switch(pathname) {
case '/public/bundle.js':
res.writeHead(200, jsHeader)
return fs.createReadStream('./public/bundle.js').pipe(res)
default:
res.writeHead(200, {
'Content-Type': 'text/html',
'Link': '<http://localhost:8000/public/bundle.js>; rel="fragment-script"'
})
return res.end('')
}
})
server.listen(8000)
fragments.jsは、Response HeaderにLinkヘッダを追加するようにします。Tailorは、このヘッダのJavascriptを読み込むことになります。
さらに、fragments.jsは、Linkヘッダで指定されたリクエストを return fs.createReadStream('./public/bundle.js').pipe(res) でストリームのパイプを返すそうです。
Lerna

それぞれのフラグメントをLernaで管理するようにします。 私は、下記のようなpackages分けをしました。
- common
- 共通する変数・ライブラリ
- fragment
- LitElementのカスタムエレメント定義
- function
- フラグメントと連携する関数 (ヒストリーやイベントなど)
具体的に言うと、次のようなものを用意しました。
| directoy name | package name |
|---|---|
| packages/common-module | @type/common-module |
| packages/common-variable | @type/common-variable |
| packages/fragment-auth-components | @auth/fragment-auth-components |
| packages/fragment-product-item | @product/fragment-product-item |
| packages/fragment-search-box | @search/fragment-search-box |
| packages/function-event-hub | @controller/function-event-hub |
| packages/function-history-navigation | @controller/function-history-navigation |
| packages/function-renderer-proxy | @controller/function-renderer-proxy |
| packages/function-search-api | @search/function-search-api |
| packages/function-service-worker | @type/function-service-worker |
どの名前も、その時の気分で雑に設定したので、気にしないでください。(笑) 伝えたいのは、@XXX が1チームで管理する領域みたいなことをしたかっただけです。
packageを使いたい場合は、次のような依存を設定します。
package.json
{
"dependencies": {
"@controller/function-event-hub": "^0.0.0",
"@type/common-variable": "^0.0.0",
}
}
LitElement

lit-element.polymer-project.org
LitElement A simple base class for creating fast, lightweight web components
純粋なWebComponentsだけを使えばよかったのですが、次のような理由で LitElementを使いました。
まあ、特にこだわりはないです。 書き方は、次のとおりです。
import {LitElement, html, customElement, css, property} from 'lit-element';
@customElement('product-item')
export class ProductItem extends LitElement {
static styles = css`
:host {
display: block;
border: solid 1px gray;
padding: 16px;
max-width: 800px;
}
`;
@property({type: String})
name = ``;
render() {
return html`<div>${this.name}</div>`;
}
}
declare global {
interface HTMLElementTagNameMap {
'product-item': ProductItem;
}
}
LitElement + Typescript では、open-testing を使ってテストすることができます。 github.com
また、jestでもテストができるようです。
DynamicRendering

このサンプルでは、カスタムエレメントを使って、ブラウザ側でレンダリングする 所謂SPAの動きで構築しています。 『SEOガー!』とSSRしなきゃと思う訳ですが、正直SSRを考えたくないです。(ハイドレーションなんて無駄なロードをブラウザにさせたくない) 次の記事のように、ボットのアクセスのみに、ダイナミックレンダリングした結果(SPAのレンダリング結果HTML)を返すようにしたいです。
技術的には、次のようなものを使えば良いです。
function-renderer-proxy/src/renderer.ts
... const page = await this.browser.newPage(); // browser: Puppeteer.Browser ... const result = await page.content() as string; // Puppeteerのレンダリング結果コンテンツ(HTML)
要は、Puppeteerで実際にレンダリングさせた結果をBotに返却しているだけです。
EventHub
フラグメント同士は、CustomEventを通して連携します。
https://developer.mozilla.org/ja/docs/Web/Guide/Events/Creating_and_triggering_eventsdeveloper.mozilla.org
全て、このCustomEventとAddEventListenerを管理するEventHub(packages名)を経由するようにします。(理想)
History
ページ全体のヒストリーは、HistoryNavigation(packages名)で管理したいと考えています。(理想)
また、ルーティングを制御する Web Components向けライブラリ vaadin/router も便利そうだったので導入してみました。
ShareModule
LitElementのようなどこでも使っているライブラリは、共通化してバンドルサイズを縮めたいです。 Webpackのようなバンドルツールには、ExternalやDLLPlugin、ModuleFederationなどの共通化機能があります。
今回は、externalを使っています。
common-module/common.js
exports['rxjs'] = require('rxjs')
exports['lit-element'] = require('lit-element')
exports['graphql-tag'] = require('graphql-tag')
exports['graphql'] = require('graphql')
exports['apollo-client'] = require('apollo-client')
exports['apollo-cache-inmemory'] = require('apollo-cache-inmemory')
exports['apollo-link-http'] = require('apollo-link-http')
common-module/webpack.config.js
module.exports = {
entry: './common.js',
output: {
path: __dirname + '/public',
publicPath: 'http://localhost:6006/public/',
filename: 'bundle.js',
libraryTarget: 'amd'
}
}
共通化したライブラリは、次のTailorのindex.htmlで読み込みます。
templates/index.html
<script>
(function (d) {
require(d);
var arr = [
'lit-element',
'rxjs',
'graphql-tag',
'apollo-client',
'apollo-cache-inmemory',
'apollo-link-http',
'graphql'
];
while (i = arr.pop()) (function (dep) {
define(dep, d, function (b) {
return b[dep];
})
})(i);
}(['http://localhost:6006/public/bundle.js']));
</script>
そうすると、例えばsearchBoxのwebpackでは、次のようなことが使えます。
fragment-search-box/webpack.config.js
externals: {
'lit-element': 'lit-element',
'graphql-tag': 'graphql-tag',
'apollo-client': 'apollo-client',
'apollo-cache-inmemory': 'apollo-cache-inmemory',
'apollo-link-http': 'apollo-link-http',
'graphql': 'graphql'
}
その他
その時の気分で導入したものを紹介します。(or 導入しようと考えたもの)
GraphQL
APIは、雑にGraphQLを採用しました。特に理由はありません。
SkeltonUI
Skelton UIも使ってみたいなと思っていました。
Reactを使わなくても、CSSの@keyframesを使えば良いでしょう。が、まあ使っていません。(笑)
Rxjs
typescriptの処理をリアクティブな雰囲気でコーディングしたかったので導入してみました。
(リアクティブに詳しい人には、怒られそうな理由ですね...笑)
所感
これまで、Podium、Ara-Framework, そして Tailor といったMicro Frontendsに関わるサーバーサイド統合ライブラリを使ってみました。
silverbirder180.hatenablog.com silverbirder180.hatenablog.com
これらは、どれも考え方が良いなと思っています。 Podiumのフラグメントのインターフェース設計、Ara-FrameworkのRenderとデータ取得の明確な分離、そしてTailorのストリーム統合です。 しかし、これらは良いライブラリではありますが、プロダクションとしてはあんまり採用したくない(依存したくない)と思っています。
むしろ、もっと昔から使われていた Edge Side Includeや Server Side Include などを使ったサーバーサイド統合の方が魅力的です。 例えば、Edge Worker とか良さそうです。(HTTP2やHTTP3も気になります)
まあ、まだ納得いくMicro Frontendsの設計が発見できていないので、これからも検証し続けようと思います。
Ara-Framework で Micro Frontends with SSR

Photo by Artem Sapegin on Unsplash
みなさん、こんにちは。silverbirder です。 私の最近の興味として、Micro Frontends があります。 silverbirder180.hatenablog.com 今、Ara-Frameworkというフレームワークを使った Micro Frontends のアプローチ方法を学んでいます。
Ara-Framework とは
Build Micro-frontends easily using Airbnb Hypernova
※ https://ara-framework.github.io/website/
Ara-Frameworkは、Airbnbが開発したHypernovaというフレームワークを使って、Micro Frontendsを構築します。
Airbnb Hypernova とは
A service for server-side rendering your JavaScript views
※ https://github.com/airbnb/hypernova
簡単に説明すると、Hypernovaはデータを渡せばレンダリング結果(HTML)を返却してくれるライブラリです。 これにより、データ構築とレンダリングを明確に分離することができるメリットがあります。
Ara-Framework アーキテクチャ
Ara-Frameworkのアーキテクチャ図は、次のようなものです。
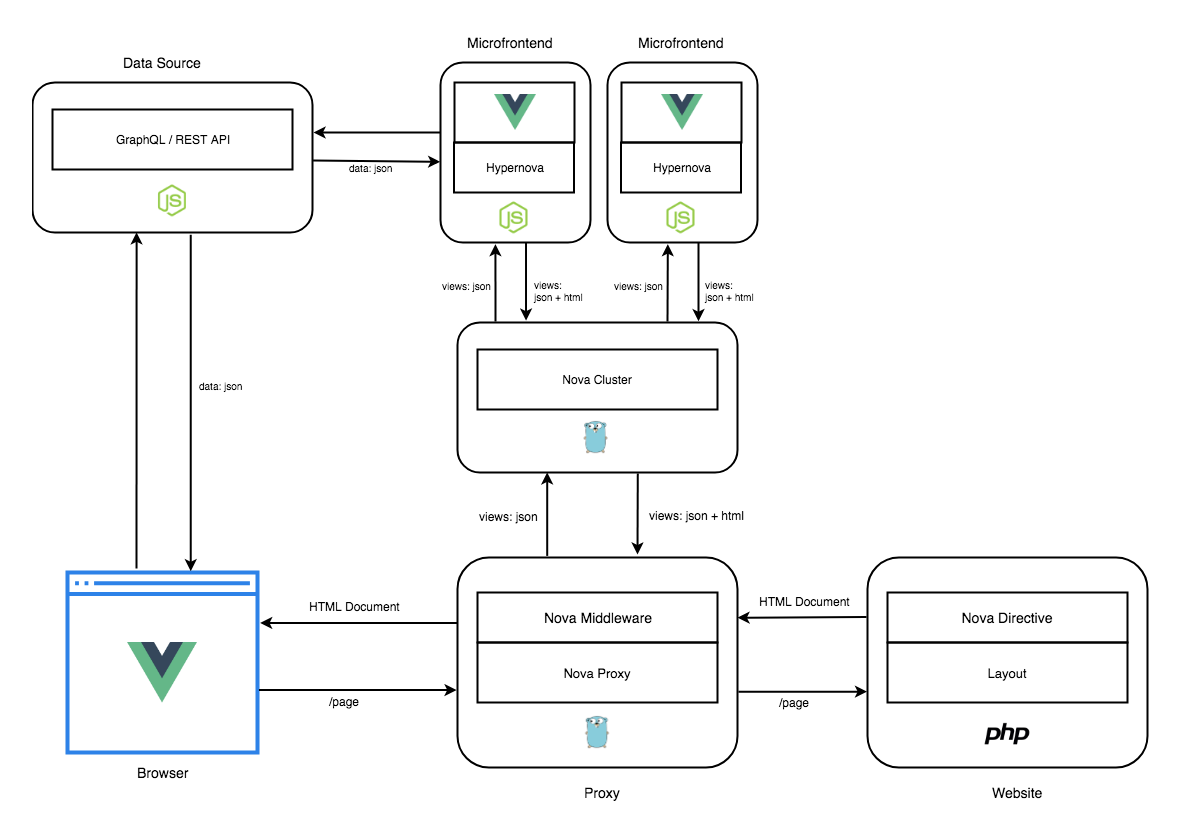
※ https://ara-framework.github.io/website/docs/nova-architecture
構成要素は、次のとおりです。(↑の公式ページにも説明があります)
- Nova Proxy
- Nova Directive (Layout)
- 全体のHTMLを構築します。Hypernovaのプレースホルダーを埋め込みます。
- Node.js, Laravel, Jinja2 が対応しています。
- Nova Cluster
- Nova Bindingを管理するクラスタです。
- Nova ProxyとNova Bindings の間に位置します。
- Nova Bindings (Hypernova)
- データを渡されて、HTMLをレンダリングした結果を返します。 (Hypernovaをここで使います)
- React, Vue.js, Angular, Svelte, Preact が対応しています。
このように、LayoutとRendering (Nova Bindings) を明確に分けることで、独立性、スケーラビリティ性が良いのかなと感じます。 各レイアの間にキャッシュレイヤを設けることでパフォーマンス向上も期待できます。
詳しくは、公式ページをご確認下さい。
Ara-Framework サンプルコード
Ara-Frameworkを実際に使ってみました。サンプルコードは下記にあげています。 github.com
package.json はこんな感じです。
package.json
"scripts": { "cluster": "cd cluster && PORT=5000 ara run:cluster --config ./views.json", "layout": "cd layout && PORT=8080 node ./bin/www", "proxy": "cd proxy && HYPERNOVA_BATCH=http://localhost:5000/batch PORT=8000 ara run:proxy --config ./nova-proxy.json", "search:dev": "cd search && PORT=3000 ./node_modules/webpack/bin/webpack.js --watch --mode development", "product:dev": "cd product && PORT=3001 ./node_modules/webpack/bin/webpack.js --watch --mode development", "dev": "concurrently -n cluster,layout,proxy,search,product \"npm run cluster\" \"npm run layout\" \"npm run proxy\" \"npm run search:dev\" \"npm run product:dev\"", }
作っていく手順は、次の流れです。
- Nova Proxy を作成
- Nova Directive (Layout) を作成
- Nova Cluster を作成
- Nova Bindings (Hypernova) を作成
Ara-Framework を使うためには、次の準備をしておく必要があります。
$ npm i -g ara-cli
Nova Proxy
Nova Proxyは、Nova DirectiveへProxyしますので、そのhostを書きます。
nova-proxy.json
{ "locations": [ { "path": "/", "host": "http://localhost:8080", "modifyResponse": true } ] }
また、Nova Proxyは、Nova Clusterへ問い合わせするため、HYPERNOVA_BATCH という変数にURLを指定する必要があります。
Nova Proxyを動かすときは、次のコマンドを実行します。
$ HYPERNOVA_BATCH=http://localhost:5000/batch PORT=8000 ara run:proxy --config ./nova-proxy.json
Nova Directive (Layout)
Nova Directvieは、hypernova-handlebars-directive を使います。
これは、Node.jsのhandlebarsテンプレートエンジン(hbs)で使えます。
Expressの雛形を生成します。
$ npx express-generator -v hbs layout
詳細は割愛しますが、次のHTMLファイル(hbs)を作成します。
※ 詳しくはこちら https://ara-framework.github.io/website/docs/render-on-page
layout/index.hbs
<h1>{{title}}</h1>
<p>Welcome to {{title}}</p>
{{>nova name="Search" data-title=title }}
<script src="http://localhost:3000/public/client.js"></script>
<script src="http://localhost:3001/public/client.js"></script>
{{>nova}} がHypernovaのプレースホルダーである hypernova-handlebars-directive です。
nameは、Nova Bindingsの名前 (後ほど説明します)、data-*は、Nova Bindingsに渡すデータです。
また、scriptでclient.jsをloadしているのは、CSRを実現するためです。
動かすのは、Expressを動かすときと同じで、次になります。
$ PORT=8080 node ./bin/www
Nova Cluster
Nova Clusterは、Nova Bindingsを管理します。
views.json
{ "Search": { "server": "http://localhost:3000/batch" }, "Product": { "server": "http://localhost:3001/batch" } }
SearchやProductは、後ほど作成するNova Bindingsの名前です。serverは、Nova Bindingsが動いているURLです。
Nova Clusterを動かすときは、次のコマンドを実行します。
$ PORT=5000 ara run:cluster --config ./views.json
Nova Bindings
Nova Bindings を作るために、次のコマンドを実行します。
$ ara new:nova search -t react $ ara new:nova product -t vue
そこから、自動生成されたディレクトリから、少し修正したものが次のとおりです。
search/Search.jsx
import React, { Component } from 'react'
import { Nova } from 'nova-react-bridge'
class Search extends Component {
render() {
<div>
<div>Search Components!</div>
<table>
<tr>
{['🐙', '🐳', '🐊', '🐍', '🐷', '🐶', '🐯'].map((emoji, key) => {
return <td key={key}>
<Nova
name="Product"
data={{title: emoji}}/>
</td>
})}
</tr>
</table>
</div>
}
}
今までの説明ではなかったですが、Nova Bridge である nova-react-bridge を使っています。
これは、Nova Directiveに似ているのですが、使えるファイルが ReactやVue.jsなどのJSフレームワークに対応しています。
そのため、Nuxt.jsやNext.js,Gatsby.js にも使えるようになります。
※ わかりにくいですが、このサンプルのNova Bridgeは、CSRで動作します。SSRで動作させるためには、Nova Proxyを挟む必要が (たぶん) あります。
product/Product.vue
<template>
<div>{{title}}</div>
</template>
<script>
export default {
props: ['title']
}
</script>
Nova Bindingsのこれらを動作させるためには、次のコマンドを実行します。
# search $ PORT=3000 ./node_modules/webpack/bin/webpack.js --watch --mode development # product $ PORT=3001 ./node_modules/webpack/bin/webpack.js --watch --mode development
動作確認
今まで紹介したものを同時に実行する必要があります。
そこで、concurrently を使います。
$ concurrently -n cluster,layout,proxy,search,product "npm run cluster" "npm run layout" "npm run proxy" "npm run search:dev" "npm run product:dev"
動作として、次のような画像になります。

最後に
繰り返しますが、Ara-Framework を使うとデータ構築(Nova Directive)とレンダリング(Nova Bindings)を明確に分離できます。 また、レンダリング部分は、それぞれ独立できます。今回紹介していないAPI部分は、誰がどのように管理するのか考える必要があります。
ただ、Nova Bindingsで使用するCSR用javascriptは、重複するコードが含まれてしまい、ブラウザロード時間が長くなってしまいます。 そこで、webpack 5から使えるようになったFederation機能を使って解決するとった手段があります。
Ara-Frameworkの紹介でした!
Apache Beam + Kotlin 開発 実践入門
 Photo by tian kuan on Unsplash
Photo by tian kuan on Unsplash
どうも、こんにちは。Re:ゼロ2期 始まりましたね👏、 @silver_birder です。 最近、仕事の関係上、Apache Beam + Kotlin を使うことになりました。それらの技術が一切知らなかったので、この記事に学んだことを書いていきます✍️。
サンプルリポジトリは、下記に載せています。
Apache Beam とは
BatchやStreaming を1つのパイプライン処理 として実現できるデータパイプライン、それがApache Beamです。(Batch + Stream → Beam)
言語は、Java, Python, Go(experimental)が選べます。 また、パイプライン上で実行する環境のことをランナーと呼び、Cloud DataflowやApache Flink、Apache Sparkなどがあります。
※ Streaming処理は、サーバーの能力がボトルネックになりがちです。そこで、Cloud DataflowというGCPのマネージドサービスを使用すると、その問題が解消されます。
機械学習など豊富な 分析ライブラリ を使いたい場合は、Python、 型安全な 開発をしたい場合は、Java を選べば良いかなと思います。
今回は、Javaを選びました。モダンな書き方ができるKotlinでコーディングします。
セットアップ
ソフトウェアバージョンは、次のとおりです。
$ java -version openjdk version "1.8.0_252" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_252-b09) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.252-b09, mixed mode)
IDEとしてintelliJを使用しており、Kotlin SDK(1.3.72)が内蔵しています。
$ git clone https://github.com/Silver-birder/apache-beam-kotlin-example.git && cd apache-beam-kotlin-example $ ./gradlew build
パイプライン処理の概要
1. データの入力する(input → PCollection) 2. 入力されたデータを変形させる (PCollection → PTransform → PCollection) 3. 加工したデータを出力する (PCollection → output)
PCollectionは、ひとかたまりのデータセットだと思って下さい。
よくあるサンプルコード WordCount を例に進めます。
※ 元々は、ApacheBeam公式のWordCountがあったのですが、ローカルマシン単体で動かせないため、多少アレンジしました。WordCountは、ある文章から単語を抽出しカウントを取るだけです。
メインのコードは、こちらです。動かすときは、IDEからデバッグ実行します。(この辺りは省略します。詳しくはMakefileを見て下さい🙇♂️)
@JvmStatic fun main(args: Array<String>) { val options = (PipelineOptionsFactory.fromArgs(*args).withValidation().`as`(WordCountOptions::class.java)) runWordCount(options) } @JvmStatic fun runWordCount(options: WordCountOptions) { // パイプラインを作る(空っぽ) val p = Pipeline.create(options) // Textファイルからデータを入力する → PCollection p.apply("ReadLines", TextIO.read().from(options.inputFile)) // PCollectionをPTransformで変形させる .apply(CountWords()) .apply(MapElements.via(FormatAsTextFn())) // Textファイルにデータ(PCollection)を出力する .apply<PDone>("WriteCounts", TextIO.write().to(options.output)) // パイプラインを実行する p.run().waitUntilFinish() }
PTransform
Apache BeamのコアとなるPTransform についてサンプルコードを載せます。
ParDo
ParDoは、PCollectionを好きなように加工することができます。 最も、柔軟に処理を書くことができます。
// PTransformによる変形処理 public class CountWords : PTransform<PCollection<String>, PCollection<KV<String, Long>>>() { override fun expand(lines: PCollection<String>): PCollection<KV<String, Long>> { // 文章を単語に分割する val words = lines.apply(ParDo.of(ExtractWordsFn())) // 分割された単語をカウントする val wordCounts = words.apply(Count.perElement()) return wordCounts } } public class ExtractWordsFn : DoFn<String, String>() { @ProcessElement fun processElement(@Element element: String, receiver: DoFn.OutputReceiver<String>) { ... }
GroupByKey
Key-Value(KV)のPCollectionをKeyでグルーピングします。
import java.lang.Iterable as JavaIterable // PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollection<KV<String, JavaIterable<Long>>> val groupByWord = wordCounts.apply(GroupByKey.create<String, Long>()) as PCollection<KV<String, JavaIterable<Long>>>
Kotlinでは、Iterableが動作できないため、JavaのIterableを使う必要があります。
Flatten
複数のPCollectionを1つのPCollectionに結合します。
// PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollectionList<KV<String, Long>> val wordCountsDouble = PCollectionList.of(wordCounts).and(wordCounts) // PCollection<KV<String, Long>> val flattenWordCount = wordCountsDouble.apply(Flatten.pCollections())
Combine
PCollectionの要素を結合します。 GroupByKeyのKey毎に要素を結合する方法と、PCollection毎に要素を結合する方法があります。 今回は、GroupByKeyのサンプルコードです。
// PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollection<KV<String, Long>> val sumWordsByKey = wordCounts.apply(Sum.longsPerKey())
Partition
PCollectionを任意の数でパーティション分割します。
// PCollection<KV<String, Long>> val wordCounts = words.apply(Count.perElement()) // PCollection<KV<String, Long>> var 10wordCounts = wordCounts.apply(Partition.of(10, PartitionFunc()))
StreamingとWindowing
パイプラインを、そのまま使えばBatch実行となります。 Batchは、有限のデータに対し、Streamingは無限のデータに対して使います。 無限のデータを処理するのは、Windowingというものを使い、無限を有限のデータにカットして、処理します。
Streaming処理するためには、下記のようにコードにします。
@JvmStatic fun main(args: Array<String>) { val options = (PipelineOptionsFactory.fromArgs(*args).withValidation().`as`(WordCountOptions::class.java)) runWordCount(options) } @JvmStatic fun runWordCount(options: WordCountOptions) { val p = Pipeline.create(options) p.apply("ReadLines", TextIO .read() .from("./src/main/kotlin/*.json") // fromで指定したファイルがないか監視する。(入力値は無限) // 10秒ごとに監視、5分間変更がなければ終了。 .watchForNewFiles(standardSeconds(10), afterTimeSinceNewOutput(standardMinutes(5))) ) // 30秒間毎にWindowingする。(無限のデータを、有限のデータにカットする) .apply(Window.into<String>(FixedWindows.of(standardSeconds(30)))) .apply(CountWords()) .apply(MapElements.via(FormatAsTextFn())) .apply<PDone>("WriteCounts", TextIO.write().to(options.output).withWindowedWrites().withNumShards(1)) p.run().waitUntilFinish() }
テストコード
Apache Beamもテストコードが書けます。 サンプルコードは、こちらです。
実行するパイプラインをTestPipelineにすることで、テストができます。
import org.apache.beam.sdk.testing.TestPipeline fun countWordsTest() { // Arrange val p: Pipeline = TestPipeline.create().enableAbandonedNodeEnforcement(false) val input: PCollection<String> = p.apply(Create.of(WORDS)).setCoder(StringUtf8Coder.of()) val output: PCollection<KV<String, Long>>? = input.apply(CountWords()) // Act p.run() // Assert PAssert.that<KV<String, Long>>(output).containsInAnyOrder(COUNTS_ARRAY) } companion object { val WORDS: List<String> = listOf( "hi there", "hi", "hi sue bob", "hi sue", "", "bob hi" ) val COUNTS_ARRAY = listOf( KV.of("hi", 5L), KV.of("there", 2L), KV.of("sue", 2L), KV.of("bob", 2L) ) }
終わりに
Apache Beamは、他にも Side inputやAdditional outputsなどがあります。 使いこなせるためにも、これからも頑張っていきます!
さて、Re:ゼロ2期を見ましょう👍
Webアプリのテスト観点を調べてまとめてみた (25選)
 最近、Property Based Test という言葉を知りました。
他にどういうテストの種類があるのか気になったので、調べてみました。
本記事は、テストの種類を列挙します。
※ 使用する技術は、私の都合上、node.jsで選んでいます。
最近、Property Based Test という言葉を知りました。
他にどういうテストの種類があるのか気になったので、調べてみました。
本記事は、テストの種類を列挙します。
※ 使用する技術は、私の都合上、node.jsで選んでいます。
- テスト観点一覧
- Cache Test
- Code Size Test
- Complexity Test
- Copy&Paste Test
- Cross Browser/Platform Test
- E2E Test
- Exception Test
- Flaky Test
- Integration Test
- Logging Test
- Monkey Test
- Multi Tenanct Test
- Mutation Test
- Chaos Test
- Performance Test
- Property Based Test
- Regression Test
- Robustness Test
- Security Test
- SEO Test
- Smoke Test
- Snapshot Test
- Static Test
- Unit Test
- Visual Regression Test
- 最後に
テスト観点一覧
Cache Test
Webアプリでは、様々なCacheが使われます。 例えば、ブラウザCache、CDN Cache、プロキシCache、バックエンドCache などなどです。 Cacheは、便利な反面、使いすぎると、どこがどうCacheしているのか迷子になってしまいます。 Webアプリでも、Cacheをテストする必要がありそうです。
Code Size Test
大きなサイズのJSライブラリを読み込むと、レスポンスタイムが悪化してしまいます。そこで、常にコードサイズを計測する必要があります。
github.com

Complexity Test
循環的複雑度(Cyclomatic complexity)は、制御文(ifやfor)の複雑さを計測します。 複雑なコードは、バグの温床になりがちなので、極力シンプルなコードを心がけたいところです。
Copy&Paste Test
Copy&Pasteは、DRYの原則に反するため、特別な理由がない限りは、してはいけません。Copy&Pasteを検出するツールがあるみたいです。
github.com

Cross Browser/Platform Test
サポートするブラウザや、プラットフォーム(iOS,Android,Desktopなど)の動作検証が必要です。 そのため、サポートするブラウザやプラットフォームの環境を準備しなければなりません。 そういう環境を手軽に使えるサービスがあったりします。
E2E Test
Webアプリを、端から端まで (End To End: E2E)を検証します。 例えば、ユーザーがWebアプリを訪れて、クリックや入力するなど、使ってみることです。 このテストは、不安定なテスト(よく失敗する)になりがちなので、安定稼働できるような取り組みが必要です。 例えば、操作する処理の抽象化や、データ固定などです。
Exception Test
正常系、準正常系、異常系などのテストが必要です。 準正常系は、システムが意図的にエラーとしているものです。例えば、フォーム入力値エラーとかです。 異常系は、システムが意図せずエラーとなるものです。例えば、Timeoutエラーとかです。
また、Javaが得意な人なら知っているであろう、検査例外や非検査例外という例外の扱い方があります。 基本的には検査例外はエラーハンドリングし、非検査例外はエラーハンドリングしない方針が良いです。
Flaky Test
不安定なテストのことを指します。これに対するアプローチ方法の1つに、Google社の資料があります。
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/45880.pdf
日本人がまとめて頂いたものが、次の資料です。 speakerdeck.com
Integration Test
Integration Testは、Unit Testのような単一機能を統合した検証になります。 定義によりますが、私は『Unit Testでは発見できないようなもの』かなと思います。 Unit Testでカバーできていなくても、他のテストで検証できていれば、Integration Testは不要になります。
Logging Test
ログ出力が適切なレベルで出力されているか検証する必要があります。 INFO, WARN, ERRORなどがルールに基づいて使い分けされているか気になります。 ログを出すことができるかどうかは、ログライブラリの検証になりますので、必要ないかもしれませんが、 意図したタイミングで、意図したログレベルで、意図したメッセージが出力されるかは、テストしても良いと思います。
Monkey Test
お猿さんがランダムにテストするような、モンキーテストです。 テストのパターン網羅が難しい場合や、パターン網羅できているけどダメ押しで、このテストをします。
github.com

Multi Tenanct Test
マルチテナントは、企業者(利用者)毎に区別した、同一のシステムを提供する方式です。 これは、企業毎にサブドメインを分けたりするため、その環境毎のテストが必要になります。
Mutation Test
テストを検証するため、突然変異テストというものがあります。 プロダクトコードを破壊することで、テストも壊れるかどうかを検証します。 もし、プロダクトコードを壊しても、テストが成功してしまうと、それは正しくテストできていません。
github.com

Chaos Test
障害を注入した際に、どういった動きになるのかを検証するテストです。
Performance Test
パフォーマンスと言っても、 CPU使用率、メモリ使用率、レスポンスタイム、RPS など様々な指標があります。 これらを計測し、SLOなどの基準値を満たせているかを検証しておく必要があります。
Property Based Test
データを半自動生成し、テストをする手法です。
Regression Test
Regression Testは、修正した内容が意図せず他の箇所に影響を及ぼしていないか(デグレーション)を確認するテストです。 このテストは幅広い意味を持つので、ここに内容されるテスト種類は多いと思います。
Robustness Test
Webアプリは、ロバストであるべきです。 何かしらWebアプリ内で障害が発生したとしても、最低限のサービスだけでも提供するのが好まれます。 もちろん、その際のHTTPステータスを200にせず、障害にあったステータスを返しましょう。
Security Test
セキュリティのテストは、どんなWebアプリでも必須になります。 セキュリティの専門家ではないので、どういうテストが必要なのかは、ここでは割愛します。
依存するパッケージ脆弱性検査には、下記のコマンドが有効です。
npm audit fix
SEO Test
Webアプリへ流入数を改善するためには、SEOは不可欠です。 lighthouseというツールでSEOスコアを見ることができるみたいです。
github.com

Smoke Test
Smoke Testは、Webアプリが最低限動作するために必要なケースを確保する検証です。 例えば、トップページへリクエストしたら、レスポンスがHTTP 200で返却されるとかです。
この最低限の動作保証がなければ、これ以上の詳細なテストができません。 個人的には、Smoke Test → E2E Test の順で進むのかなと思っています。
Snapshot Test
Webアプリへリクエストし、そのレスポンスであるHTML(スナップショット)を保存します。 このHTMLが、変更前と比較して変化がないかの検証をするのが、Snapshot testです。 リファクタリングなど、変化がない修正に対して有効です。
Static Test
Static Testは、Webアプリを動かさなくても検証できるテストです。 よくあるのが、Linter です。
HTML github.com
JS github.com
Commit github.com
Docker github.com
これらは、プルリクエストで機械的に指摘する Danger との相性が良いです。 github.com
Unit Test
単一機能をテストするUnit Testがあります。このUnit Testが全てPASSしたら、 他のテストを進めるのが一般的かなと思います。
Code Coverage
Unitテストで、どこをテストできたかのカバレッジを見ることができます。 感覚としては、全体の8割を満たしていれば良いかなと思います。
https://jestjs.io/docs/en/cli.html#--coverageboolean
実際に動作しているJSやCSSのカバレッジを収集することもできます。
speakerdeck.com puppeteer_coverage.js · GitHub
Visual Regression Test
見た目の変化を監視する必要があります。例えば、リンク切れとかがあれば、検出するべきです。
github.com

最後に
どういうテストの観点があるのか、調べたり、経験則よりざっと書いてみました。 全てをテストする必要はなく、『どういう動作の品質を担保したいか』を意識して、 取捨選択するのが良いと思います。 最後まで読んでいただき、ありがとございます。